Monte Carlo Range Forecast [DW]This is an experimental study designed to forecast the range of price movement from a specified starting point using a Monte Carlo simulation.
Monte Carlo experiments are a broad class of computational algorithms that utilize random sampling to derive real world numerical results.
These types of algorithms have a number of applications in numerous fields of study including physics, engineering, behavioral sciences, climate forecasting, computer graphics, gaming AI, mathematics, and finance.
Although the applications vary, there is a typical process behind the majority of Monte Carlo methods:
-> First, a distribution of possible inputs is defined.
-> Next, values are generated randomly from the distribution.
-> The values are then fed through some form of deterministic algorithm.
-> And lastly, the results are aggregated over some number of iterations.
In this study, the Monte Carlo process used generates a distribution of aggregate pseudorandom linear price returns summed over a user defined period, then plots standard deviations of the outcomes from the mean outcome generate forecast regions.
The pseudorandom process used in this script relies on a modified Wichmann-Hill pseudorandom number generator (PRNG) algorithm.
Wichmann-Hill is a hybrid generator that uses three linear congruential generators (LCGs) with different prime moduli.
Each LCG within the generator produces an independent, uniformly distributed number between 0 and 1.
The three generated values are then summed and modulo 1 is taken to deliver the final uniformly distributed output.
Because of its long cycle length, Wichmann-Hill is a fantastic generator to use on TV since it's extremely unlikely that you'll ever see a cycle repeat.
The resulting pseudorandom output from this generator has a minimum repetition cycle length of 6,953,607,871,644.
Fun fact: Wichmann-Hill is a widely used PRNG in various software applications. For example, Excel 2003 and later uses this algorithm in its RAND function, and it was the default generator in Python up to v2.2.
The generation algorithm in this script takes the Wichmann-Hill algorithm, and uses a multi-stage transformation process to generate the results.
First, a parent seed is selected. This can either be a fixed value, or a dynamic value.
The dynamic parent value is produced by taking advantage of Pine's timenow variable behavior. It produces a variable parent seed by using a frozen ratio of timenow/time.
Because timenow always reflects the current real time when frozen and the time variable reflects the chart's beginning time when frozen, the ratio of these values produces a new number every time the cache updates.
After a parent seed is selected, its value is then fed through a uniformly distributed seed array generator, which generates multiple arrays of pseudorandom "children" seeds.
The seeds produced in this step are then fed through the main generators to produce arrays of pseudorandom simulated outcomes, and a pseudorandom series to compare with the real series.
The main generators within this script are designed to (at least somewhat) model the stochastic nature of financial time series data.
The first step in this process is to transform the uniform outputs of the Wichmann-Hill into outputs that are normally distributed.
In this script, the transformation is done using an estimate of the normal distribution quantile function.
Quantile functions, otherwise known as percent-point or inverse cumulative distribution functions, specify the value of a random variable such that the probability of the variable being within the value's boundary equals the input probability.
The quantile equation for a normal probability distribution is μ + σ(√2)erf^-1(2(p - 0.5)) where μ is the mean of the distribution, σ is the standard deviation, erf^-1 is the inverse Gauss error function, and p is the probability.
Because erf^-1() does not have a simple, closed form interpretation, it must be approximated.
To keep things lightweight in this approximation, I used a truncated Maclaurin Series expansion for this function with precomputed coefficients and rolled out operations to avoid nested looping.
This method provides a decent approximation of the error function without completely breaking floating point limits or sucking up runtime memory.
Note that there are plenty of more robust techniques to approximate this function, but their memory needs very. I chose this method specifically because of runtime favorability.
To generate a pseudorandom approximately normally distributed variable, the uniformly distributed variable from the Wichmann-Hill algorithm is used as the input probability for the quantile estimator.
Now from here, we get a pretty decent output that could be used itself in the simulation process. Many Monte Carlo simulations and random price generators utilize a normal variable.
However, if you compare the outputs of this normal variable with the actual returns of the real time series, you'll find that the variability in shocks (random changes) doesn't quite behave like it does in real data.
This is because most real financial time series data is more complex. Its distribution may be approximately normal at times, but the variability of its distribution changes over time due to various underlying factors.
In light of this, I believe that returns behave more like a convoluted product distribution rather than just a raw normal.
So the next step to get our procedurally generated returns to more closely emulate the behavior of real returns is to introduce more complexity into our model.
Through experimentation, I've found that a return series more closely emulating real returns can be generated in a three step process:
-> First, generate multiple independent, normally distributed variables simultaneously.
-> Next, apply pseudorandom weighting to each variable ranging from -1 to 1, or some limits within those bounds. This modulates each series to provide more variability in the shocks by producing product distributions.
-> Lastly, add the results together to generate the final pseudorandom output with a convoluted distribution. This adds variable amounts of constructive and destructive interference to produce a more "natural" looking output.
In this script, I use three independent normally distributed variables multiplied by uniform product distributed variables.
The first variable is generated by multiplying a normal variable by one uniformly distributed variable. This produces a bit more tailedness (kurtosis) than a normal distribution, but nothing too extreme.
The second variable is generated by multiplying a normal variable by two uniformly distributed variables. This produces moderately greater tails in the distribution.
The third variable is generated by multiplying a normal variable by three uniformly distributed variables. This produces a distribution with heavier tails.
For additional control of the output distributions, the uniform product distributions are given optional limits.
These limits control the boundaries for the absolute value of the uniform product variables, which affects the tails. In other words, they limit the weighting applied to the normally distributed variables in this transformation.
All three sets are then multiplied by user defined amplitude factors to adjust presence, then added together to produce our final pseudorandom return series with a convoluted product distribution.
Once we have the final, more "natural" looking pseudorandom series, the values are recursively summed over the forecast period to generate a simulated result.
This process of generation, weighting, addition, and summation is repeated over the user defined number of simulations with different seeds generated from the parent to produce our array of initial simulated outcomes.
After the initial simulation array is generated, the max, min, mean and standard deviation of this array are calculated, and the values are stored in holding arrays on each iteration to be called upon later.
Reference difference series and price values are also stored in holding arrays to be used in our comparison plots.
In this script, I use a linear model with simple returns rather than compounding log returns to generate the output.
The reason for this is that in generating outputs this way, we're able to run our simulations recursively from the beginning of the chart, then apply scaling and anchoring post-process.
This allows a greater conservation of runtime memory than the alternative, making it more suitable for doing longer forecasts with heavier amounts of simulations in TV's runtime environment.
From our starting time, the previous bar's price, volatility, and optional drift (expected return) are factored into our holding arrays to generate the final forecast parameters.
After these parameters are computed, the range forecast is produced.
The basis value for the ranges is the mean outcome of the simulations that were run.
Then, quarter standard deviations of the simulated outcomes are added to and subtracted from the basis up to 3σ to generate the forecast ranges.
All of these values are plotted and colorized based on their theoretical probability density. The most likely areas are the warmest colors, and least likely areas are the coolest colors.
An information panel is also displayed at the starting time which shows the starting time and price, forecast type, parent seed value, simulations run, forecast bars, total drift, mean, standard deviation, max outcome, min outcome, and bars remaining.
The interesting thing about simulated outcomes is that although the probability distribution of each simulation is not normal, the distribution of different outcomes converges to a normal one with enough steps.
In light of this, the probability density of outcomes is highest near the initial value + total drift, and decreases the further away from this point you go.
This makes logical sense since the central path is the easiest one to travel.
Given the ever changing state of markets, I find this tool to be best suited for shorter term forecasts.
However, if the movements of price are expected to remain relatively stable, longer term forecasts may be equally as valid.
There are many possible ways for users to apply this tool to their analysis setups. For example, the forecast ranges may be used as a guide to help users set risk targets.
Or, the generated levels could be used in conjunction with other indicators for meaningful confluence signals.
More advanced users could even extrapolate the functions used within this script for various purposes, such as generating pseudorandom data to test systems on, perform integration and approximations, etc.
These are just a few examples of potential uses of this script. How you choose to use it to benefit your trading, analysis, and coding is entirely up to you.
If nothing else, I think this is a pretty neat script simply for the novelty of it.
----------
How To Use:
When you first add the script to your chart, you will be prompted to confirm the starting date and time, number of bars to forecast, number of simulations to run, and whether to include drift assumption.
You will also be prompted to confirm the forecast type. There are two types to choose from:
-> End Result - This uses the values from the end of the simulation throughout the forecast interval.
-> Developing - This uses the values that develop from bar to bar, providing a real-time outlook.
You can always update these settings after confirmation as well.
Once these inputs are confirmed, the script will boot up and automatically generate the forecast in a separate pane.
Note that if there is no bar of data at the time you wish to start the forecast, the script will automatically detect use the next available bar after the specified start time.
From here, you can now control the rest of the settings.
The "Seeding Settings" section controls the initial seed value used to generate the children that produce the simulations.
In this section, you can control whether the seed is a fixed value, or a dynamic one.
Since selecting the dynamic parent option will change the seed value every time you change the settings or refresh your chart, there is a "Regenerate" input built into the script.
This input is a dummy input that isn't connected to any of the calculations. The purpose of this input is to force an update of the dynamic parent without affecting the generator or forecast settings.
Note that because we're running a limited number of simulations, different parent seeds will typically yield slightly different forecast ranges.
When using a small number of simulations, you will likely see a higher amount of variance between differently seeded results because smaller numbers of sampled simulations yield a heavier bias.
The more simulations you run, the smaller this variance will become since the outcomes become more convergent toward the same distribution, so the differences between differently seeded forecasts will become more marginal.
When using a dynamic parent, pay attention to the dispersion of ranges.
When you find a set of ranges that is dispersed how you like with your configuration, set your fixed parent value to the parent seed that shows in the info panel.
This will allow you to replicate that dispersion behavior again in the future.
An important thing to note when settings alerts on the plotted levels, or using them as components for signals in other scripts, is to decide on a fixed value for your parent seed to avoid minor repainting due to seed changes.
When the parent seed is fixed, no repainting occurs.
The "Amplitude Settings" section controls the amplitude coefficients for the three differently tailed generators.
These amplitude factors will change the difference series output for each simulation by controlling how aggressively each series moves.
When "Adjust Amplitude Coefficients" is disabled, all three coefficients are set to 1.
Note that if you expect volatility to significantly diverge from its historical values over the forecast interval, try experimenting with these factors to match your anticipation.
The "Weighting Settings" section controls the weighting boundaries for the three generators.
These weighting limits affect how tailed the distributions in each generator are, which in turn affects the final series outputs.
The maximum absolute value range for the weights is . When "Limit Generator Weights" is disabled, this is the range that is automatically used.
The last set of inputs is the "Display Settings", where you can control the visual outputs.
From here, you can select to display either "Forecast" or "Difference Comparison" via the "Output Display Type" dropdown tab.
"Forecast" is the type displayed by default. This plots the end result or developing forecast ranges.
There is an option with this display type to show the developing extremes of the simulations. This option is enabled by default.
There's also an option with this display type to show one of the simulated price series from the set alongside actual prices.
This allows you to visually compare simulated prices alongside the real prices.
"Difference Comparison" allows you to visually compare a synthetic difference series from the set alongside the actual difference series.
This display method is primarily useful for visually tuning the amplitude and weighting settings of the generators.
There are also info panel settings on the bottom, which allow you to control size, colors, and date format for the panel.
It's all pretty simple to use once you get the hang of it. So play around with the settings and see what kinds of forecasts you can generate!
----------
ADDITIONAL NOTES & DISCLAIMERS
Although I've done a number of things within this script to keep runtime demands as low as possible, the fact remains that this script is fairly computationally heavy.
Because of this, you may get random timeouts when using this script.
This could be due to either random drops in available runtime on the server, using too many simulations, or running the simulations over too many bars.
If it's just a random drop in runtime on the server, hide and unhide the script, re-add it to the chart, or simply refresh the page.
If the timeout persists after trying this, then you'll need to adjust your settings to a less demanding configuration.
Please note that no specific claims are being made in regards to this script's predictive accuracy.
It must be understood that this model is based on randomized price generation with assumed constant drift and dispersion from historical data before the starting point.
Models like these not consider the real world factors that may influence price movement (economic changes, seasonality, macro-trends, instrument hype, etc.), nor the changes in sample distribution that may occur.
In light of this, it's perfectly possible for price data to exceed even the most extreme simulated outcomes.
The future is uncertain, and becomes increasingly uncertain with each passing point in time.
Predictive models of any type can vary significantly in performance at any point in time, and nobody can guarantee any specific type of future performance.
When using forecasts in making decisions, DO NOT treat them as any form of guarantee that values will fall within the predicted range.
When basing your trading decisions on any trading methodology or utility, predictive or not, you do so at your own risk.
No guarantee is being issued regarding the accuracy of this forecast model.
Forecasting is very far from an exact science, and the results from any forecast are designed to be interpreted as potential outcomes rather than anything concrete.
With that being said, when applied prudently and treated as "general case scenarios", forecast models like these may very well be potentially beneficial tools to have in the arsenal.
In den Scripts nach "THE SCRIPT" suchen

Relative Volume at Time█ OVERVIEW
This indicator calculates relative volume, which is the ratio of present volume over an average of past volume.
It offers two calculation modes, both using a time reference as an anchor.
█ CONCEPTS
Calculation modes
The simplest way to calculate relative volume is by using the ratio of a bar's volume over a simple moving average of the last n volume values.
This indicator uses one of two, more subtle ways to calculate both values of the relative volume ratio: current volume:past volume .
The two calculations modes are:
1 — Cumulate from Beginning of TF to Current Bar where:
current volume = the cumulative volume since the beginning of the timeframe unit, and
past volume = the mean of volume during that same relative period of time in the past n timeframe units.
2 — Point-to-Point Bars at Same Offset from Beginning of TF where:
current volume = the volume on a single chart bar, and
past volume = the mean of volume values from that same relative bar in time from the past n timeframe units.
Timeframe units
Timeframe units can be defined in three different ways:
1 — Using Auto-steps, where the timeframe unit automatically adjusts to the timeframe used on the chart:
— A 1 min timeframe unit will be used on 1sec charts,
— 1H will be used for charts at 1min and less,
— 1D will be used for other intraday chart timeframes,
— 1W will be used for 1D charts,
— 1M will be used for charts at less than 1M,
— 1Y will be used for charts at greater or equal than 1M.
2 — As a fixed timeframe that you define.
3 — By time of day (for intraday chart timeframes only), which you also define. If you use non-intraday chart timeframes in this mode, the indicator will switch to Auto-steps.
Relative Relativity
A relative volume value of 1.0 indicates that current volume is equal to the mean of past volume , but how can we determine what constitutes a high relative volume value?
The traditional way is to settle for an arbitrary threshold, with 2.0 often used to indicate that relative volume is worthy of attention.
We wanted to provide traders with a contextual method of calculating threshold values, so in addition to the conventional fixed threshold value,
this indicator includes two methods of calculating a threshold channel on past relative volume values:
1 — Using the standard deviation of relative volume over a fixed lookback.
2 — Using the highs/lows of relative volume over a variable lookback.
Channels calculated on relative volume provide meta-relativity, if you will, as they are relative values of relative volume.
█ FEATURES
Controls in the "Display" section of inputs determine what is visible in the indicator's pane. The next "Settings" section is where you configure the parameters used in the calculations. The "Column Coloring Conditions" section controls the color of the columns, which you will see in three of the five display modes available. Whether columns are plotted or not, the coloring conditions also determine when markers appear, if you have chosen to show the markers in the "Display" section. The presence of markers is what triggers the alerts configured on this indicator. Finally, the "Colors" section of inputs allows you to control the color of the indicator's visual components.
Display
Five display modes are available:
• Current Volume Columns : shows columns of current volume , with past volume displayed as an outlined column.
• Relative Volume Columns : shows relative volume as a column.
• Relative Volume Columns With Average : shows relative volume as a column, with the average of relative volume.
• Directional Relative Volume Average : shows a line calculated using the average of +/- values of relative volume.
The positive value of relative volume is used on up bars; its negative value on down bars.
• Relative Volume Average : shows the average of relative volume.
A Hull moving average is used to calculate the average used in the three last display modes.
You can also control the display of:
• The value or relative volume, when in the first three display modes. Only the last 500 values will be shown.
• Timeframe transitions, shown in the background.
• A reminder of the active timeframe unit, which appears to the right of the indicator's last bar.
• The threshold used, which can be a fixed value or a channel, as determined in the next "Settings" section of inputs.
• Up/Down markers, which appear on transitions of the color of the volume columns (determined by coloring conditions), which in turn control when alerts are triggered.
• Conditions of high volatility.
Settings
Use this section of inputs to change:
• Calculation mode : this is where you select one of this indicator's two calculation modes for current volume and past volume , as explained in the "Concepts" section.
• Past Volume Lookback in TF units : the quantity of timeframe units used in the calculation of past volume .
• Define Timeframes Units Using : the mode used to determine what one timeframe unit is. Note that when using a fixed timeframe, it must be higher than the chart's timeframe.
Also, note that time of day timeframe units only work on intraday chart timeframes.
• Threshold Mode : Five different modes can be selected:
— Fixed Value : You can define the value using the "Fixed Threshold" field below. The default value is 2.0.
— Standard Deviation Channel From Fixed Lookback : This is a channel calculated using the simple moving average of relative volume
(so not the Hull moving average used elsewhere in the indicator), plus/minus the standard deviation multiplied by a user-defined factor.
The lookback used is the value of the "Channel Lookback" field. Its default is 100.
— High/Low Channel From Beginning of TF : in this mode, the High/Low values reset at the beginning of each timeframe unit.
— High/Low Channel From Beginning of Past Volume Lookback : in this mode, the High/Low values start from the farthest point back where we are calculating past volume ,
which is determined by the combination of timeframe units and the "Past Volume Lookback in TF units" value.
— High/Low Channel From Fixed Lookback : In this mode the lookback is fixed. You can define the value using the "Channel Lookback" field. The default value is 100.
• Period of RelVol Moving Average : the period of the Hull moving average used in the "Directional Relative Volume Average" and the "Relative Volume Average".
• High Volatility is defined using fast and slow ATR periods, so this represents the volatility of price.
Volatility is considered to be high when the fast ATR value is greater than its slow value. Volatility can be used as a filter in the column coloring conditions.
Column Coloring Conditions
• Eight different conditions can be turned on or off to determine the color of the volume columns. All "ON" conditions must be met to determine a high/low state of relative volume,
or, in the case of directional relative volume, a bull/bear state.
• A volatility state can also be used to filter the conditions.
• When the coloring conditions and the filter do not allow for a high/low state to be determined, the neutral color is used.
• Transitions of the color of the volume columns determined by coloring conditions are used to plot the up/down markers, which in turn control when alerts are triggered.
Colors
• You can define your own colors for all of the oscillator's plots.
• The default colors will perform well on light or dark chart backgrounds.
Alerts
• An alert can be defined for the script. The alert will trigger whenever an up/down marker appears in the indicator's display.
The particular combination of coloring conditions and the display settings for up/down markers when you create the alert will determine which conditions trigger the alert.
After alerts are created, subsequent changes to the conditions controlling the display of markers will not affect existing alerts.
• By configuring the script's inputs in different ways before you create your alerts, you can create multiple, functionally distinct alerts from this script.
When creating multiple alerts, it is useful to include in the alert's message a reminder of the particular conditions you used for each alert.
• As is usually the case, alerts triggering "Once Per Bar Close" will prevent repainting.
Error messages
Error messages will appear at the end of the chart upon the following conditions:
• When the combination of the timeframe units used and the "Past Volume Lookback in TF units" value create a lookback that is greater than 5000 bars.
The lookback will then be recalculated to a value such that a runtime error does not occur.
• If the chart's timeframe is higher than the timeframe units. This error cannot occur when using Auto-steps to calculate timeframe units.
• If relative volume cannot be calculated, for example, when no volume data is available for the chart's symbol.
• When the threshold of relative volume is configured to be visible but the indicator's scale does not allow it to be visible (in "Current Volume Columns" display mode).
█ NOTES
For traders
The chart shown here uses the following display modes: "Current Volume Columns", "Relative Volume Columns With Average", "Directional Relative Volume Average" and "Relative Volume Average". The last one also shows the threshold channel in standard deviation mode, and the TF Unit reminder to the right, in red.
Volume, like price, is a value with a market-dependent scale. The only valid reference for volume being its past values, any improvement in the way past volume is calculated thus represents a potential opportunity to traders. Relative volume calculated as it is here can help traders extract useful information from markets in many circumstances, markets with cyclical volume such as Forex being one, obvious case. The relative nature of the values calculated by this indicator also make it a natural fit for cross-market and cross-sector analysis, or to identify behavioral changes in the different futures contracts of the same market. Relative volume can also be put to more exotic uses, such as in evaluating changes in the popularity of exchanges.
Relative volume alone has no directional bias. While higher relative volume values always indicate higher trading activity, that activity does not necessarily translate into significant price movement. In a tightly fought battle between buyers and sellers, you could theoretically have very large volume for many bars, with no change whatsoever in bid/ask prices. This of course, is unlikely to happen in reality, and so traders are justified in considering high relative volume values as indicating periods where more attention is required, because imbalances in the strength of buying/selling power during high-volume trading periods can amplify price variations, providing traders with the generally useful gift of volatility.
Be sure to give the "Directional Relative Volume Average" a try. Contrary to the always-positive ratio widely used in this indicator, the "Directional Relative Volume Average" produces a value able to determine a bullish/bearish bias for relative volume.
Note that realtime bars must be complete for the relative volume value to be confirmed. Values calculated on historical or elapsed realtime bars will not recalculate unless historical volume data changes.
Finally, as with all indicators using volume information, keep in mind that some exchanges/brokers supply different feeds for intraday and daily data, and the volume data on both feeds can sometimes vary quite a bit.
For coders
Our script was written using the PineCoders Coding Conventions for Pine .
The description was formatted using the techniques explained in the How We Write and Format Script Descriptions PineCoders publication.
Bits and pieces of code were lifted from the MTF Selection Framework and the MTF Oscillator Framework , also by PineCoders.
█ THANKS
Thanks to dgtrd for suggesting to add the channel using standard deviation.
Thanks to adolgov for helpful suggestions on calculations and visuals.
Look first. Then leap.

Weekly/Daily/Hourly/Minutes Colored Background IntervalsThis is my "Weekly/Daily/Hourly/Minutes Colored Background Intervals" assistant. I wouldn't describe it as an indicator, it just exhibits coloration of referenced periods of time with bgcolor() in Pine. With the arrival of 2021, I pondered the necessity of needing a visualization pre-2021 to visually recognize periodicity of market movements by the week, day, hour, or an adjustable period of minutes. While this script is simply generic, I hope you may find useful in your endeavors as a member on TradingView.
Explaining the script's usage, the "Minutes" input can be adjusted from anywhere between 5-55 minutes for only intraday. This can be modified to accommodate 90 minutes (1.5hrs) or any other minutes period desirable by tweaking certain numbers up to 1440. Minutes and Hourly backgrounds are disabled by default for most daily traders. Changing the input() code to `true` will provide them on by default when the script loads, if you choose that route. Each time periods background color is enable/disable capable. All of the colors are easily adjustable to any combination you can ponder for your visual acuity with the color swatch provided by input(type=input.color). The coloring can be "swapped" by input() depending on how you wish to start and end the day visually. I thought this would come in handy. The weekly background can have different starting points, whether it be Sunday, Monday, or any other day such as Friday for example.
The entire script's contents isn't intended for complete re-use as is for publicly published scripts. It's more along the lines of code that could be used to personally modify indicators you have, depending on the time frames you may actually be trading on. The code is basically modular, so you can use bits and pieces of it in your personally modified Pine Editor scripts that you wish to customize for yourself. I will say that the isXxx() functions are completely reusable in any script without any need for author permission inquiries from me, as easy as copy and paste. Those may come in handy for many folks. If you find them useful in certain circumstances, use isXxx() functions as you please. Day of the week detection by functions will have applications beyond my current intended use for them.
Of notable mention, this is a miniature lesson by example of how the new input(type=input.color) may be used. I'm also using `var` inside functions to aid in computational efficiency of the script runtime. The colors are permanently stored at the very beginning of the scripts operation inside the function and just reused from that point onward. Its a rare use case, but well suited for this scripts intention. Once again I have demonstrated the "Power of Pine" for developers of any experience level to learn from via code elegance.
When available time provides itself, I will consider your inquiries, thoughts, and concepts presented below in the comments section, should you have any questions or comments regarding this indicator. When my indicators achieve more prevalent use by TV members , I may implement more ideas when they present themselves as worthy additions. Have a profitable future everyone!

Synthetic Implied APROverview
The Synthetic Implied APR is an artificial implied APR, designed to imitate the implied APR seen when trading cryptocurrency funding rates. It combines real-time funding rates with premium data to calculate an artificial market expectation of the annualized funding rate.
The (actual) implied APR is the market's expectation of the annualized funding rate. This is dependent on bid/ask impacts of the implied APR, something which is currently unavailable to fetch with TradingView. In essence, an implied APR of X% means traders believe that asset's funding fees to average X% when annualized.
What's important to understand, is that the actual value of the synthetic implied APR is not relevant. We only simply use its relative changes when we trade (i.e if it crosses above/below its MA for a given weight). Even for the same asset, the implied APRs will change depending on days to maturity.
How it calculates
The synthetic implied APR is calculated with these steps:
Collects premium data from perpetual futures markets using optimized lower timeframe requests (check my 'Predicted Funding Rates' indicator)
Calculates the funding rate by adding the premium to an interest rate component (clamped within exchange limits)
Derives the underlying APR from the 8-hour funding rate (funding rate × 3 × 365)
Apply a weighed formula that imitates both the direction (underlying APR) with the volatility of prices (from the premium index and funding)
premium_component = (prem_avg / 50 ) * 365
weighedprem = (weight * fr) + ((1 - weight) * apr) + (premium_component * 0.3)
impliedAPR = math.avg(weighedprem, ta.sma(apr, maLength))
How to use it: Generally
Preface: Funding rates are an indication of market sentiment
If funding is positive, generally the market is bullish as longs are willing to pay shorts funding
If funding is negative, generally the market is bearish as shorts are willing to pay longs funding
So, this script can be used like a typical oscillator:
Bullish: If implied APR > MA OR if implied APR MA is green
Bearish: If implied APR < MA OR if implied APR MA is red
The components:
Synthetic Implied APR: The main metric. At current setting of 0.7, it imitates volatility
Weight: The higher the value, the smoother the synthetic implied APR is (and MA too). This value is very important to the imitation. At 0.7, it imitates the actual volatility of the implied APR. At weight = 1, it becomes very smooth. Perfect for trading
Synthetic Implied APR Moving Average: A moving average of the Synthetic implied APR. Can choose from multiple selections, (SMA, EMA, WMA, HMA, VWMA, RMA)
How to use it: Trading Funding
When trading funding there're multiple ways to use it with different settings
Trade funding rates with trend changes
Settings: Weight = 1
Method 1: When the implied APR MA turns green, long funding rates (or short if red)
Method 2: When the implied APR crosses above the MA, long funding rates (or short when crosses below)
Trade funding rates with MA pullbacks
Settings: Weight = 0.7, timeframe 15m
In an uptrend: When implied APR crosses below then above the script, long funding opportunity
In an downtrend: When implied APR crosses above then below the script, shortfunding opportunity
You can determine the trend with the method before, using a weight of 1
To trade funding rates, it's best to have these 3 scripts at these settings:
Predicted Funding Rates: This allows you to see the predicted funding rates and see if they've maxxed out for added confluence too (+/-0.01% usually for Binance BTC futures)
Synthetic implied APR: At weight 1, the MA provides a good trend (whether close above/below or colour change)
Synthetic implied APR: At weight 0.7, it provides a good imitation of volatility
How to use it: Trading Futures
When trading futures:
You can determine roughly what the trend is, if the assumption is made that funding rates can help identify trends if used as a sentiment indicator. It should be supplemented with traditional trend trading methods
To prevent whipsaws, weight should remain high
Long trend: When the implied APR MA turns green OR when it crosses above its MA
Short trend: When the implied APR MA turns red OR when it below above its MA
Why it's original
This indicator introduces a unique synthetic weighting system that combines funding rates, underlying APR, and premium components in a way not found in existing TradingView scripts. Trading funding rates is a niche area, there aren't that many scripts currently available. And to my knowledge, there's no synthetic implied APR scripts available on TradingView either. So I believe this script to be original in that sense.
Notes
Because it depends on my triangular weighting algos, optimal accuracy is found on timeframes that are 4H or less. On higher timeframes, the accuracy drops off. Best timeframes for intraday trading using this are 15m or 1 hour
The higher the timeframe, the lower the MA one should use. At 1 hour, 200 or higher is best. At say, 4h, length of 50 is best
Only works for coins that have a Binance premium index
Inputs
Funding Period - Select between "1 Hour" or "8 Hour" funding cycles. 8 hours is standard for Binance
Table - Toggle the information dashboard on/off to show or hide real-time metrics including funding rate, premium, and APR value
Weight - Controls the balance between funding rate (higher values = smoother) and APR (lower values = more responsive) in the calculation, ranging from 0.0 to 1.0. Default is 0.7, this imitates the volatility
Auto Timeframe Implied Length - Automatically calculates optimal smoothing length based on your chart timeframe for consistent behavior across different time periods
Manual Implied Length - Sets a fixed smoothing length (in bars) when auto mode is disabled, with lower values being more responsive and higher values being smoother
Show Implied APR MA - Displays an additional moving average line of the Synthetic Implied APR to help identify trend direction and crossover signals
MA Type for Implied APR - Selects the calculation method (SMA, EMA, WMA, HMA, VWMA, or RMA) for the moving average, each offering different responsiveness and lag characteristics
MA Length for Implied APR - Sets the lookback period (1-500 bars) for the moving average, with shorter lengths providing more signals and longer lengths filtering noise
Show Underlying APR - Displays the raw APR calculation (without synthetic weighting) as a reference line to compare against the main indicator
Bullish Color - Sets the color for positive values in the table and rising MA line
Bearish Color - Sets the color for negative values in the table and falling MA line
Table Background - Customizes the background color and transparency of the information dashboard
Table Text Color - Sets the color for label text in the left column of the information table
Table Text Size - Controls the font size of table text with options from Tiny to Huge

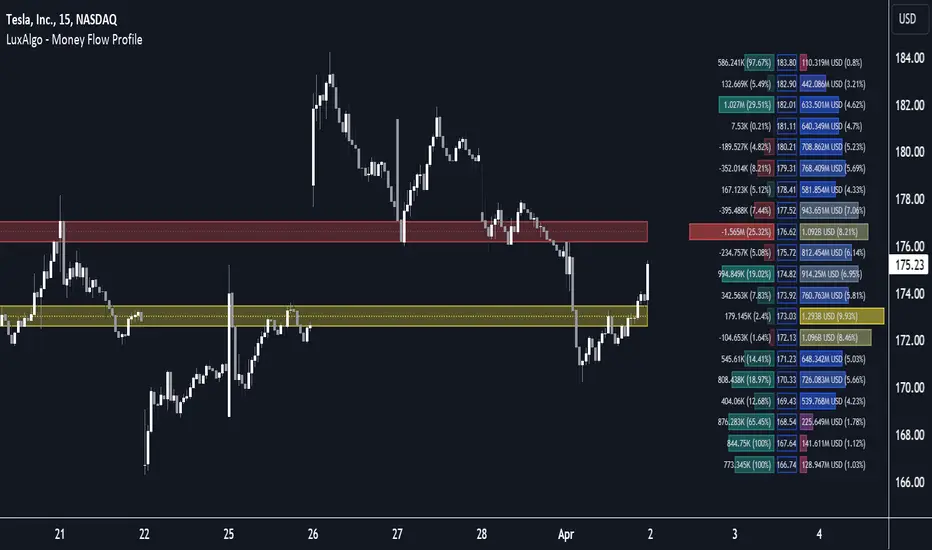
Money Flow Profile [LuxAlgo]The Money Flow Profile is a charting tool that measures the traded volume or the money flow at all price levels on the market over a specified time period and highlights the relationship between the price of a given asset and the willingness of traders to either buy or sell it, allowing traders to reveal dominant and/or significant price levels and to analyze the trading activity of a particular user-selected range.
This tool combines a volume/money flow profile, a sentiment profile, and price levels, where the right side of the profile highlights the distribution of the traded activity/money flow at different price levels, the left side of the profile highlights the market sentiment at those price levels, and in the middle the price levels.
🔶 USAGE
A volume/money flow profile is an advanced charting tool that displays the traded volume/money flow at different price levels over a specific period. It helps traders visualize where the majority of trading activity/money flow has occurred.
A sentiment profile is a difference between buy and sell volume/money flow aiming to highlight the sentiment/dominance at specific price levels.
Each row of the profile presents figures on volume and money flow specific to price levels.
High volume/money flow nodes indicate areas of high activity and are likely to act as support or resistance in the future. They attract price and try to hold it there. Conversely, low-volume nodes are areas with low trading activity, that are less subject to get revisited by the price. The market often bounces right over these levels, not staying for long. The "Profile Heatmap" option of the script helps to better emphasize the trading activity within each areas.
By measuring the traded activity at each price level the script presents an ability to highlight the consolidation zones, in other words, highlights accumulation and distribution zones. When the price moves toward one end of the consolidation and volume pick up, it can foreshadow a potential breakout.
Level of Significance, Point of Control, Highest Sentiment Zone, and Profile Price levels are some of the other profile-related options available with the script.
🔶 SETTINGS
The script takes into account user-defined parameters and plots the profiles, where detailed usage for each user-defined input parameter in indicator settings is provided with the related input's tooltip.
🔹 Profile Generic Settings
Lookback Length / Fixed Range: Sets the lookback length.
Profile Source: Sets the profile source, Volume, or Money Flow.
🔹 Profile Presentation Settings
Volume/Money Flow Profile: Toggles the visibility of the Volume/Money Flow Profile.
High Traded Nodes: Threshold and Color option for high traded nodes.
Average Traded Nodes: Color option for average traded nodes.
Low Traded Nodes: Threshold and Color option for low traded nodes.
🔹 Sentiment Profile Settings
Sentiment Profile: Toggles the visibility of the Sentiment Profile.
Sentiment Polarity Method: Sets the method used to calculate the up/down volume/money flow.
Bullish Nodes: Color option for Bullish Nodes.
Bearish Nodes: Color option for Bearish Nodes.
🔹 Profile Heatmap Settings
Profile Heatmap: Toggles the visibility of the profile heatmap.
Heatmap Source: Sets the source of the profile heatmap, Volume/Money Flow Profile, or Sentiment Profile.
Heatmap Transparency: Control the transparency of the profile heatmap.
🔹 Other Presentation Settings
Level of Significance: Toggles the visibility of the level of significance line/zone.
Consolidation Zones: Toggles the visibility of the consolidation zones.
Consolidation Threshold, Color: Sets the threshold value and zone color.
Highest Sentiment Zone: Toggles the visibility of the highest bullish or bearish sentiment zone.
Profile Price Levels, Color, Size: Toggles the visibility of the profile price levels, and sets the color and the size of the level labels.
Profile Range Background Fill: Toggles the visibility of the profiles range.
🔹 Other Settings
Number of Rows: Specify how many rows each profile histogram will have.
Profile Width %: Alters the width of the rows in the histogram, relative to the profile length
Profile Text Size: Alters the size of the text. Setting to Auto will keep the text within the box limits.
Profile Horizontal Offset: Enables to move profile in the horizontal axis.
🔶 RELATED SCRIPTS
Liquidity-Sentiment-Profile
Swing-Volume-Profiles
For more and other conceptual scripts you are kindly invited to visit LuxAlgo-Scripts .
Bogdan Ciocoiu - Sniper EntryWhat is Sniper Entry
Sniper Entry is a set indicator that encapsulates a collection of pre-configured scripts using specific variables that enable users to extract signals by interpreting market behaviour quickly, suitable for 1-3min scalping. This instrument is a tool that acts as a confluence for traders to make decisions concerning current market conditions. This indicator does not apply solely to an asset.
What Sniper Entry is not
Sniper Entry is not interpreting fundamental analysis and will also not be providing out of box market signals. Instead, it will provide a collection of integrated and significantly improved open-source subscripts designed to help traders speculate on market trends. Traders must apply their strategies and configure Sniper Entry accordingly to maximise the script's output.
Originality and usefulness
The collection of subscripts encapsulated in this tool makes it unique in the Trading View ecosystem. This indicator enables traders to consider entry positions or exit positions by comparing similar algorithms at once.
Its usefulness also emerges from the unique configurations embedded in the indicator's settings, which are different from those of the original scripts.
This indicator's originality is also reflected in how its modules are integrated, including the integration of the settings.
Open-source reuse
I used the following open-source resources, which I simplified significantly and pre-configured for short term scalping. The source codes for the below are already in the public domain, including the following links listed below.
www.tradingview.com (open source)
(open source and generic algorithm)
www.tradingview.com (open source)
(open source)
(open source)
www.tradingview.com (generic MA algorithm and open source)
(generic VWAP algorithm and open source)

String Manipulation Framework [PineCoders FAQ]█ OVERVIEW
This script provides string manipulation functions to help Pine coders.
█ FUNCTIONS PROVIDED
f_strLeft(_str, _n)
Function returning the leftmost `_n` characters in `_str`.
f_strRight(_str, _n)
Function returning the rightmost `_n` characters in `_str`.
f_strMid(_str, _from, _to)
Function returning the substring of `_str` from character position `_from` to `_to` inclusively.
f_strLeftOf(_str, _of)
Function returning the sub-string of `_str` to the left of the `_of` separating character.
f_strRightOf(_str, _of)
Function returning the sub-string of `_str` to the right of the `_of` separating character.
f_strCharPos(_str, _chr)
Function returning the position of the first occurrence of `_chr` in `_str`, where the first character position is 0. Returns -1 if the character is not found.
f_strReplace(_src, _pos, _str)
Function that replaces a character at position `_pos` in the `_src` string with the `_str` character or string.
f_tickFormat()
Function returning a format string usable with `tostring()` to round a value to the symbol's tick precision.
f_tostringPad(_val, _fmt)
Function returning a string representation of a numeric `_val` using a special `_fmt` string allowing all strings to be of the same width, to help align columns of values.
`f_tostringPad()`
Using the functions should be straightforward, but `f_tostringPad()` requires more explanations. Its purpose is to help coders produce columns of fixed-width string representations of numbers which can be used to produce columns of numbers that vertically align neatly in labels, something that comes in handy when, for example, you need to center columns, yet still produce numbers of various lengths that nonetheless align.
While the formatting string used with this function resembles the one used in tostring() , it has a few additional characteristics:
• The question mark (" ? ") is used to indicate that padding is needed.
• If negative numbers must be handled by the function, the first character of the formatting string must be a minus sign ("-"),
otherwise the unary minus sign of negative numbers will be stripped out.
• You will produce more predictable results by using "0" rather than "#" in the formatting string.
You can experiment with `f_tostringPad()` formatting strings by changing the one used in the script's inputs and see the results on the chart.
These are some valid examples of formatting strings that can be used with `f_tostringPad()`:
"???0": forces strings to be four units wide, in all-positive "int" format.
"-???0": forces strings to be four units wide, plus room for a unary minus sign in the first position, in "int" format.
"???0.0": forces strings to be four units wide to the left of the point, all-positive, with a decimal point and then a mantissa rounded to a single digit.
"-???0.0?": same as above, but adds a unary minus sign for negative values, and adds a space after the single-digit mantissa.
"?????????0.0": forces the left part of the float to occupy the space of 10 digits, with a decimal point and then a mantissa rounded to a single digit.
█ CHART
The information displayed by this indicator uses the values in the script's Inputs, so you can use them to play around.
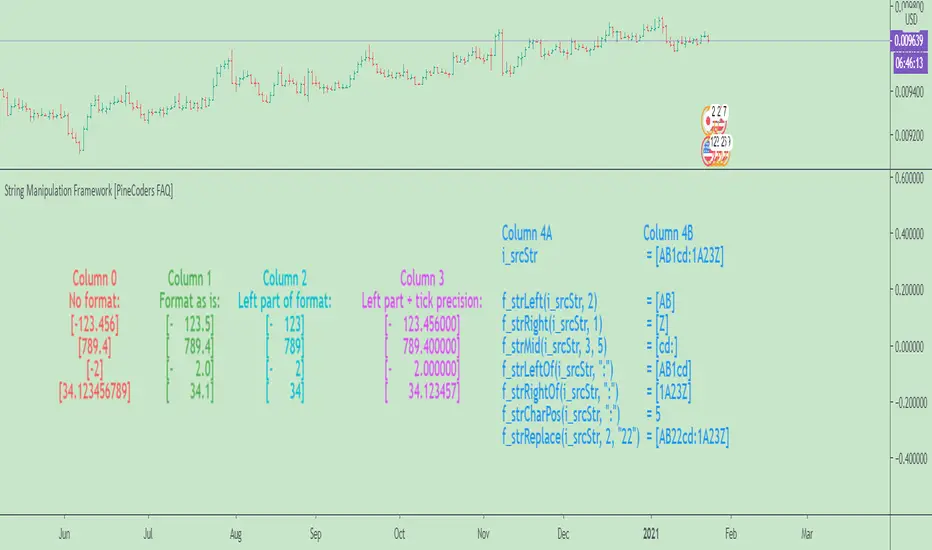
The chart shows the following information:
• Column 0 : The numeric input values in a centered column, converted to strings using tostring() without a formatting argument.
• Column 1 : Shows the values formatted using `f_tostringPad()` with the formatting string from the inputs.
• Column 2 : Shows the values formatted using `f_tostringPad()` but with only the part of the formatting string left of the decimal point, if it contains one.
• Column 3 : Shows the values formatted using `f_tostringPad()` but with the part of the formatting string left of the decimal point,
to which is added the right part of the `f_tostringPad()` formatting string, to obtain the precision in ticks of the symbol the chart is on.
• Column 4 : Shows the result of using the other string manipulation functions in the script on the source string supplied in the inputs.
It also demonstrates how to split up a label in two distinct parts so that you can vertically align columns when the leftmost part contains strings with varying lengths.
You will see in our code how we construct this column in two steps.
█ LIMITATIONS
The Pine runtime is optimized for number crunching. Too many string manipulations will take a toll on the performance of your scripts, as can readily be seen with the running time of this script. To minimize the impact of using string manipulation functions in your scripts, consider limiting their calculation to the first or last bar of the dataset when possible. This can be achieved by using the var keyword when declaring variables containing the result of your string manipulations, or by enclosing blocks of code in if blocks using barstate.isfirst or barstate.islast .
█ NOTES
To understand the challenges we face when trying to align strings vertically, it is useful to know that:
• As is the case in many other places in the TadingView UI and other docs, the Pine runtime uses the MS Trebuchet font to display label text.
• Trebuchet uses proportionally-spaced letters (a "W" takes more horizontal space than an "I"), but fixed-space digits (a "1" takes the same horizontal space as a "3").
Digits all use a figure space width, and it is this property that allows us to align numbers vertically.
The fact that letters are proportionally spaced is the reason why we can't vertically align columns using a "legend" + ":" `+ value structure when the "legend" part varies in width.
• The unary minus sign is the width of a punctuation space . We use this property to pad the beginning of numbers
when you use a "-" as the first character of the `f_tostringPad()` formatting string.
Our script was written using the PineCoders Coding Conventions for Pine .
The description was formatted using the techniques explained in the How We Write and Format Script Descriptions PineCoders publication.
█ THANKS
Thanks to LonesomeTheBlue for the `f_strReplace()` function.
Look first. Then leap.
OBV + WaveTrend Volume Scalper [GratefulFutures]This script is a combination script of three different strategies that provides buy and sell signals based on the change of volume with momentum confirmations.
Sources used:
This script relies on the outstanding scripts of the great script writer LazyBear: LazyBear
The following scripts were used in this publication:
1. A modified "On-Balance Volume Oscillator" modified from LazyBear's original script:
2. Wavetrend Oscillator with crosses, Author: LazyBear
3. Squeeze Momentum Oscillator, Author: LazyBear
This script functions based on the following criteria being true:
1. On balance volume oscillator turning from negative to positive (buy) or positive to negative (sell)
2. Squeeze Momentum value is increasing (buy) or decreasing (sell)
3. Wavetrend 1 (wt1) is greater than wavetrend 2 (wt2) (buy)/ Wavetrend 1 (wt1) is less than wavetrend 2 (wt2) (sell)
By combining these factors the indicator is able to signal exactly when net buying turns to net selling (OBV) and when this change is most advantageous to continue based on the momentum and price action of the underlying asset (SQMOMO and Wavetrend).
This allows you to pair volume and price action for a powerful tool to identify where price will reverse or continue providing exceptional entries for short term trades, especially when combined with other aspects such as support and resistance, or volume profile.
How to use:
Simply adjust the settings to your preference and read the given signals as generated.
Settings
There are multiple ways to tune the signals generated. It is set standard for my preferred use on a 1 minute chart.
OBV Oscillator Settings
The first 4 dropdowns in the Inputs section tune the On Balance Volume Oscillator (OBVO) portion of the indicator. You can choose if you want it to calculate based on close, open, high, low, or other value.
The most impactful in the entire settings is going to be the length and smoothing of the OBVO EMA. Making this number lower increasing the sensitivity to changes in volume, making the signals come quicker but is more susceptible to quick fluctuations. A value of between (5-20) is reasonable for the OBVO EMA length. There is a separate smoothing factor titled OBV Smoothing Length and below that, OBV Smoothing Type , a value of (2) is standard with "SMA" for smoothing type with a value of between 2-10 being reasonable. You may also play with these values to see what you like for your trading style.
Wavetrend Settings
The next 3 options are to modify the wavetrend portion of the indicator. I do not modify these from standard, and feel that they work appropriately on all time frames at the following values: n1 length (10), n2 length (20), Wavetrend Signal SMA length (4)
Squeeze Momentum Settings
The following 5 options through the end modify the Squeeze momentum portion of the indicator. The only one that modifies the signals generated is the KC Length , Making this number lower increasing the sensitivity to changes in price action, making the signals come quicker but is more susceptible to quick fluctuations. A value of between (18-25) is reasonable for KC Length .
Style Setting
You may select if you want to see the buy and sell signals. The following 5 options Raw OBV Osc through Squeeze Momentum allow you to see where each specific requirement was met, posted as a vertical line, but for live use it is recommended to turn all of these vertical lines off and only use the buy and sell signals.
Time Frames:
While this script is most effective on shorter time frames (1 minute for scalping and daytrading) it is also viable to use it on longer timeframes, due to the nature of its components being independent of time frame.
Examples of use - (Green and red vertical lines are for visualization purpose and are not part of the script)
SPY 1 Minute (Factory Settings):
SPX 15 minutes (Factory Settings):
Considerations
This script is meant primarily for short term trading, trades on the basis of seconds to minutes primarily. While they can be a good indication of volume lining up with momentum, it is always wise to use them in combination with other factors such as support, resistance, market structure, volume levels, or the many other techniques out there...
As Always... Happy Trading.
-Not_A_Mad_Scientist (GreatfulFutures Trade University)

Support and Resistance levels from Options DataINTRODUCTION
This script is designed to visualize key support and resistance levels derived from options data on TradingView charts. It overlays lines, labels, and boxes to highlight levels such as Put Walls (gamma support), Call Walls (gamma resistance), Gamma Flip points, Vanna levels, and more.
These levels are intended to help traders identify potential areas of price magnetism, reversal, or breakout based on options market dynamics. All calculations and visualizations are based on user-provided data pasted into the input field, as Pine Script cannot directly fetch external options data due to platform limitations (explained below).
For convenience, my website allows users to interact with a bot that will generate the string for up to 30 tickers at once getting nearly real-time data on demand (data is cached for 15min). With the output string pasted into this indicator, it's a bliss to shuffle through your portfolio and see those levels for each ticker.
The script is open-source under TradingView's terms, allowing users to study, modify, and improve it. It draws inspiration from common options-derived metrics like gamma exposure and vanna, which are widely discussed in financial literature. No external code is copied without rights; all logic is original or based on standard mathematical formulas.
How the Options Levels Are Calculated
The levels displayed by this script are not computed within Pine Script itself—instead, they rely on pre-calculated values provided by the user (via a pasted data string). These values are derived from options chain data fetched from financial APIs (e.g., using libraries like yfinance in Python). Here's a step-by-step overview of how these levels are generally calculated externally before being input into the script:
Fetching Options Data:
Historical and current options chain data for a ticker (e.g., strikes, open interest, volume, implied volatility, expirations) is retrieved for near-term expirations (e.g., up to 90 days).
Current stock price is obtained from recent history.
Gamma Support (Put Wall) and Resistance (Call Wall):
Gamma Calculation: For each option, gamma (the rate of change of delta) is computed using the Black-Scholes formula:
gamma = N'(d1) / (S * sigma * sqrt(T))
where S is the stock price, K is the strike, T is time to expiration (in years), sigma is implied volatility, r is the risk-free rate (e.g., 0.0445), and N'(d1) is the normal probability density function.
Weighted gamma is multiplied by open interest and aggregated by strike.
The Put Wall is the strike below the current price with the highest weighted gamma from puts (acting as support).
The Call Wall is the strike above the current price with the highest weighted gamma from calls (acting as resistance).
Short-term versions focus on strikes closer to the money (e.g., within 10-15% of the price).
Gamma Flip Level:
Net dealer gamma exposure (GEX) is calculated across all strikes:
GEX = sum (gamma * OI * 100 * S^2 * sign * decay)
where sign is +1 for calls/-1 for puts, and decay is 1 / sqrt(T).
The flip point is the price where net GEX changes sign (from positive to negative or vice versa), interpolated between strikes.
Vanna Levels:
Vanna (sensitivity of delta to volatility) is calculated:
vanna = -N'(d1) * d2 / sigma
where d2 = d1 - sigma * sqrt(T).
Weighted by open interest, the highest positive and negative vanna strikes are identified.
Other Levels:
S1/R1: Significant strikes with high combined open interest and volume (80% OI + 20% volume), below/above price for support/resistance.
Implied Move: ATM implied volatility scaled by S * sigma * sqrt(d/365) (e.g., for 7 days).
Call/Put Ratio: Total call contracts divided by put contracts (OI + volume).
IV Percentage: Average ATM implied volatility.
Options Activity Level: Average contracts per unique strike, binned into levels (0-4).
Stop Loss: Dynamically set below the lowest support (e.g., Put Wall, Gamma Flip), adjusted by IV (tighter in low IV).
Fib Target: 1.618 extension from Put Wall to Call Wall range.
Previous day levels are stored for comparison (e.g., to detect Call Wall movement >2.5% for alerts).
Effect as Support and Resistance in Technical Trading
Options levels like gamma walls influence price action due to market maker hedging:
Put Wall (Gamma Support): High put gamma below price creates a "magnet" effect—market makers buy stock as price falls, providing support. Traders might look for bounces here as entry points for longs.
Call Wall (Gamma Resistance): High call gamma above price leads to selling pressure from hedging, acting as resistance. Rejections here could signal trims, sells or even shorts.
Gamma Flip: Where gamma exposure flips sign, often a volatility pivot—crossing it can accelerate moves (bullish above, bearish below).
Vanna Levels: Positive/negative vanna indicate volatility sensitivity; crosses may signal regime shifts.
Implied Move: Shows expected range; prices outside suggest overextension.
S1/R1 and Fib Target: Volume/OI clusters act as classic S/R; Fib extensions project upside targets post-breakout.
In trading, these are not guarantees—combine with TA (e.g., volume, trends). High activity levels imply stronger effects; low CP ratio suggests bearish sentiment. Alerts trigger on proximities/crosses for awareness, not advice.
Limitations of the TradingView Platform for Data Pulling
TradingView's Pine Script is sandboxed for security and performance:
No direct internet access or API calls (e.g., can't fetch yfinance data in-script).
Limited to chart data/symbol info; no real-time options chains.
Inputs are static per load; updates require manual pasting.
Caching isn't persistent across sessions.
This prevents dynamic data pulling, ensuring scripts remain lightweight but requiring external tools for fresh data.
Creative Solution for On-Demand Data Pulling
To overcome these limitations, users can use external tools or scripts (e.g., Python-based) to fetch and compute levels on demand. The tool processes tickers, generates a formatted string (e.g., "TICKER:level1,level2,...;TIMESTAMP:unix;"), and users paste it into the script's input. This keeps data fresh without violating platform rules, as computation happens off-platform. For example, run a local script to query APIs and output the string—adaptable for any ticker.
Script Functionality Breakdown
Inputs: Custom data string (parsed for levels/timestamp); toggles for short-term/previous/Vanna/stop loss; style options (colors, transparency).
Parsing: Extracts levels for the chart symbol; gets timestamp for "updated ago" display.
Drawing: Lines/labels for levels; boxes for gamma zones/implied move; clears old elements on updates.
Info Panel: Top-right summary with metrics (CP ratio, IV, distances, activity); emojis for quick status.
Alerts: Conditions for proximities, crosses, bounces (e.g., 0.5% bounce from Put Wall).
Performance: Uses vars for persistence; efficient for real-time.
This script is educational—test thoroughly. Not financial advice; past performance isn't indicative of future results. Feedback welcome via TradingView comments.

Trend WaveHello Traders!
You know, I can sill remember the first time I started tinkering with Pinescript. As I had no prior programming experience, I learned by experimenting with other open-source scripts on TradingViews Marketplace. Tearing apart and combining interesting scripts to see what the output would be. @ChrisMoody was a huge source of inspiration for learning, and I wanted to thank him, as well as @TheLark for the concept behind this script.
The Trend Wave is based on @ChrisMoody's PPO-PercentileRank-Mkt-Tops-Bottoms , which also happens to be based on @TheLark's TheLark-Laguerre-PPO/ .
Within my experimentation, I found that if I isolate the ppoT & ppoB variables and plot them calculated from extremely small decimals, you can get an extremely fast reacting, mirroring trend detector.
Within the script, you have the ability to plot the background colors based on trend to make it easier to see where crossovers occured, as well as a Mirror Input to view the mirrored version of the script.
-@DayTradingOil
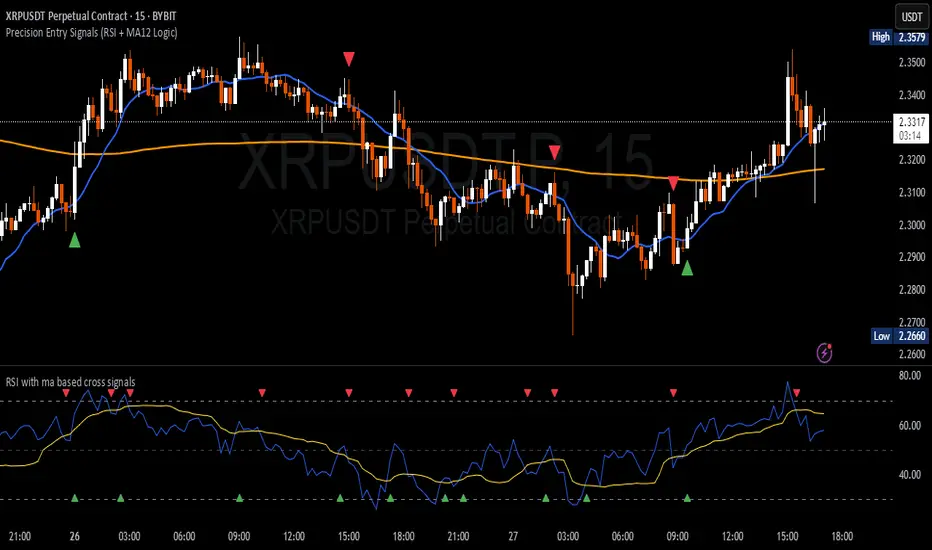
Precision Entry Signals (RSI + MA12 Logic)Description:
This script provides precise entry signals based on a clean confluence of MA12 breakouts and RSI momentum, filtered by a VWMA (Volume-Weighted Moving Average) of the RSI.
-----------------------------------------------------------------------------------------------------------------
🔹 Long entry conditions:
- Candle opens below the 12-period MA and closes above it
- RSI crosses above its VWMA
- Previous candle is bearish (additional confirmation)
🔹 Short entry conditions:
- Candle opens above the 12-period MA and closes below it
- RSI crosses below its VWMA
- Previous candle is bullish
----------------------------------------------------------------------------------------------------------------
Once a signal is confirmed, the script automatically draws:
Entry line (at close price)
Stop Loss line (just below recent lows for long, or above highs for short)
Take Profit 1 (1R)
Take Profit 2 (2R)
Labels are attached to the lines for clarity: ENTRY, SL, TP1, and TP2.
⚠️ Note: This tool only provides entry signals and visual risk/reward guidance. It does not manage exits dynamically. Manual trade management is recommended.
This script is intended for active intraday traders, especially on lower timeframes like 3-minute, 5-minute or 15-minute charts.
---------------------------------------------------------------------------------------------------------------
🔧 Recommended companion indicator:
For better confirmation and visual tracking of the RSI/VWMA cross logic, it is strongly recommended to also use the companion script:
🔹 Relative Strength Index (with MA based cross signals)
→ Shows RSI and its moving average visually, with triangle plots on every valid cross.
→ Matches exactly the RSI/VWMA behavior used in this entry signal script.
📌 Important:
After adding the RSI script to your chart, make sure to set:
RSI Length = 14
MA Type = VWMA
MA Length = 20
This ensures it visually matches the logic used by the entry signal script.
Both indicators are fully open source and meant to be used together — especially when trading manually.
Bitcoin Macro Trend Map [Ox_kali]
## Introduction
__________________________________________________________________________________
The “Bitcoin Macro Trend Map” script is designed to provide a comprehensive analysis of Bitcoin’s macroeconomic trends. By leveraging a unique combination of Bitcoin-specific macroeconomic indicators, this script helps traders identify potential market peaks and troughs with greater accuracy. It synthesizes data from multiple sources to offer a probabilistic view of market excesses, whether overbought or oversold conditions.
This script offers significant value for the following reasons:
1. Holistic Market Analysis : It integrates a diverse set of indicators that cover various aspects of the Bitcoin market, from investor sentiment and market liquidity to mining profitability and network health. This multi-faceted approach provides a more complete picture of the market than relying on a single indicator.
2. Customization and Flexibility : Users can customize the script to suit their specific trading strategies and preferences. The script offers configurable parameters for each indicator, allowing traders to adjust settings based on their analysis needs.
3. Visual Clarity : The script plots all indicators on a single chart with clear visual cues. This includes color-coded indicators and background changes based on market conditions, making it easy for traders to quickly interpret complex data.
4. Proven Indicators : The script utilizes well-established indicators like the EMA, NUPL, PUELL Multiple, and Hash Ribbons, which are widely recognized in the trading community for their effectiveness in predicting market movements.
5. A New Comprehensive Indicator : By integrating background color changes based on the aggregate signals of various indicators, this script essentially creates a new, comprehensive indicator tailored specifically for Bitcoin. This visual representation provides an immediate overview of market conditions, enhancing the ability to spot potential market reversals.
Optimal for use on timeframes ranging from 1 day to 1 week , the “Bitcoin Macro Trend Map” provides traders with actionable insights, enhancing their ability to make informed decisions in the highly volatile Bitcoin market. By combining these indicators, the script delivers a robust tool for identifying market extremes and potential reversal points.
## Key Indicators
__________________________________________________________________________________
Macroeconomic Data: The script combines several relevant macroeconomic indicators for Bitcoin, such as the 10-month EMA, M2 money supply, CVDD, Pi Cycle, NUPL, PUELL, MRVR Z-Scores, and Hash Ribbons (Full description bellow).
Open Source Sources: Most of the scripts used are sourced from open-source projects that I have modified to meet the specific needs of this script.
Recommended Timeframes: For optimal performance, it is recommended to use this script on timeframes ranging from 1 day to 1 week.
Objective: The primary goal is to provide a probabilistic solution to identify market excesses, whether overbought or oversold points.
## Originality and Purpose
__________________________________________________________________________________
This script stands out by integrating multiple macroeconomic indicators into a single comprehensive tool. Each indicator is carefully selected and customized to provide insights into different aspects of the Bitcoin market. By combining these indicators, the script offers a holistic view of market conditions, helping traders identify potential tops and bottoms with greater accuracy. This is the first version of the script, and additional macroeconomic indicators will be added in the future based on user feedback and other inputs.
## How It Works
__________________________________________________________________________________
The script works by plotting each macroeconomic indicator on a single chart, allowing users to visualize and interpret the data easily. Here’s a detailed look at how each indicator contributes to the analysis:
EMA 10 Monthly: Uses an exponential moving average over 10 monthly periods to signal bullish and bearish trends. This indicator helps identify long-term trends in the Bitcoin market by smoothing out price fluctuations to reveal the underlying trend direction.Moving Averages w/ 18 day/week/month.
Credit to @ryanman0
M2 Money Supply: Analyzes the evolution of global money supply, indicating market liquidity conditions. This indicator tracks the changes in the total amount of money available in the economy, which can impact Bitcoin’s value as a hedge against inflation or economic instability.
Credit to @dylanleclair
CVDD (Cumulative Value Days Destroyed): An indicator based on the cumulative value of days destroyed, useful for identifying market turning points. This metric helps assess the Bitcoin market’s health by evaluating the age and value of coins that are moved, indicating potential shifts in market sentiment.
Credit to @Da_Prof
Pi Cycle: Uses simple and exponential moving averages to detect potential sell points. This indicator aims to identify cyclical peaks in Bitcoin’s price, providing signals for potential market tops.
Credit to @NoCreditsLeft
NUPL (Net Unrealized Profit/Loss): Measures investors’ unrealized profit or loss to signal extreme market levels. This indicator shows the net profit or loss of Bitcoin holders as a percentage of the market cap, helping to identify periods of significant market optimism or pessimism.
Credit to @Da_Prof
PUELL Multiple: Assesses mining profitability relative to historical averages to indicate buying or selling opportunities. This indicator compares the daily issuance value of Bitcoin to its yearly average, providing insights into when the market is overbought or oversold based on miner behavior.
Credit to @Da_Prof
MRVR Z-Scores: Compares market value to realized value to identify overbought or oversold conditions. This metric helps gauge the overall market sentiment by comparing Bitcoin’s market value to its realized value, identifying potential reversal points.
Credit to @Pinnacle_Investor
Hash Ribbons: Uses hash rate variations to signal buying opportunities based on miner capitulation and recovery. This indicator tracks the health of the Bitcoin network by analyzing hash rate trends, helping to identify periods of miner capitulation and subsequent recoveries as potential buying opportunities.
Credit to @ROBO_Trading
## Indicator Visualization and Interpretation
__________________________________________________________________________________
For each horizontal line representing an indicator, a legend is displayed on the right side of the chart. If the conditions are positive for an indicator, it will turn green, indicating the end of a bearish trend. Conversely, if the conditions are negative, the indicator will turn red, signaling the end of a bullish trend.
The background color of the chart changes based on the average of green or red indicators. This parameter is configurable, allowing adjustment of the threshold at which the background color changes, providing a clear visual indication of overall market conditions.
## Script Parameters
__________________________________________________________________________________
The script includes several configurable parameters to customize the display and behavior of the indicators:
Color Style:
Normal: Default colors.
Modern: Modern color style.
Monochrome: Monochrome style.
User: User-customized colors.
Custom color settings for up trends (Up Trend Color), down trends (Down Trend Color), and NaN (NaN Color)
Background Color Thresholds:
Thresholds: Settings to define the thresholds for background color change.
Low/High Red Threshold: Low and high thresholds for bearish trends.
Low/High Green Threshold: Low and high thresholds for bullish trends.
Indicator Display:
Options to show or hide specific indicators such as EMA 10 Monthly, CVDD, Pi Cycle, M2 Money, NUPL, PUELL, MRVR Z-Scores, and Hash Ribbons.
Specific Indicator Settings:
EMA 10 Monthly: Options to customize the period for the exponential moving average calculation.
M2 Money: Aggregation of global money supply data.
CVDD: Adjustments for value normalization.
Pi Cycle: Settings for simple and exponential moving averages.
NUPL: Thresholds for unrealized profit/loss values.
PUELL: Adjustments for mining profitability multiples.
MRVR Z-Scores: Settings for overbought/oversold values.
Hash Ribbons: Options for hash rate moving averages and capitulation/recovery signals.
## Conclusion
__________________________________________________________________________________
The “Bitcoin Macro Trend Map” by Ox_kali is a tool designed to analyze the Bitcoin market. By combining several macroeconomic indicators, this script helps identify market peaks and troughs. It is recommended to use it on timeframes from 1 day to 1 week for optimal trend analysis. The scripts used are sourced from open-source projects, modified to suit the specific needs of this analysis.
## Notes
__________________________________________________________________________________
This is the first version of the script and it is still in development. More indicators will likely be added in the future. Feedback and comments are welcome to improve this tool.
## Disclaimer:
__________________________________________________________________________________
Please note that the Open Interest liquidation map is not a guarantee of future market performance and should be used in conjunction with proper risk management. Always ensure that you have a thorough understanding of the indicator’s methodology and its limitations before making any investment decisions. Additionally, past performance is not indicative of future results.

Volume Profile with Node Detection [LuxAlgo]The Volume Profile with Node Detection is a charting tool that allows visualizing the distribution of traded volume across specific price levels and highlights significant volume nodes or clusters of volume nodes that traders may find relevant in utilizing in their trading strategies.
🔶 USAGE
The volume profile component of the script serves as the foundation for node detection while encompassing all the essential features expected from a volume profile. See the sub-sections below for more detailed information about the indicator components and their usage.
🔹 Peak Volume Node Detection
A volume peak node is identified when the volume profile nodes for the N preceding and N succeeding nodes are lower than that of the evaluated one.
Displaying peak volume nodes along with their surrounding N nodes (Zones or Clusters) helps visualize the range, typically representing consolidation zones in the market. This feature enables traders to identify areas where trading activity has intensified, potentially signaling periods of price consolidation or indecision among market participants.
🔹 Trough Volume Node Detection
A volume trough node is identified when the volume profile nodes for the N preceding and N succeeding nodes are higher than that of the evaluated one.
🔹 Highest and Lowest Volume Nodes
Both the highest and lowest volume areas play significant roles in trading. The highest volume areas typically represent zones of strong price acceptance, where a significant amount of trading activity has occurred. On the other hand, the lowest volume areas signify price levels with minimal trading activity, often indicating zones of price rejection or areas where market participants have shown less interest.
🔹 Volume profile
Volume profile is calculated based on the volume of trades that occur at various price levels within a specified timeframe. It divides the price range into discrete price intervals, typically known as "price buckets" or "price bars," and then calculates the total volume of trades that occur at each price level within those intervals. This information is then presented graphically as a histogram or profile, where the height of each bar represents the volume of trades that occurred at that particular price level.
🔶 SETTINGS
🔹 Volume Nodes
Volume Peaks: Toggles the visibility of either the "Peaks" or "Clusters" on the chart, depending on the specified percentage for detection.
Node Detection Percent %: Specifies the percentage for the Volume Peaks calculation.
Volume Troughs: Toggles the visibility of either the "Troughs" or "Clusters" on the chart, depending on the specified percentage for detection.
Node Detection Percent %: Specifies the percentage for the Volume Troughs calculation.
Volume Node Threshold %: A threshold value specified as a percentage is utilized to detect peak/trough volume nodes. If a value is set, the detection will disregard volume node values lower than the specified threshold.
Highest Volume Nodes: Toggles the visibility of the highest nodes for the specified count.
Lowest Volume Nodes: Toggles the visibility of the lowest nodes for the specified count.
🔹 Volume Profile - Components
Volume Profile: Toggles the visibility of the volume profile with either classical display or gradient display.
Value Area Up / Down: Color customization option for the volume nodes within the value area of the profile.
Profile Up / Down Volume: Color customization option for the volume nodes outside of the value area of the profile.
Point of Control: Toggles the visibility of the point of control, allowing selection between "developing" or "regular" modes. Sets the color and width of the point of control line accordingly.
Value Area High (VAH): Toggles the visibility of the value area high level and allows customization of the line color.
Value Area Low (VAL): Toggles the visibility of the value area low level and allows customization of the line color.
Profile Price Labels: Toggles the visibility of the Profile Price Levels and allows customization of the text size of the levels.
🔹 Volume Profile - Display Settings
Profile Lookback Length: Specifies the length of the profile lookback period.
Value Area (%): Specifies the percentage for calculating the value area.
Profile Placement: Specify where to display the profile.
Profile Number of Rows: Specify the number of rows the profile will have.
Profile Width %: Adjusts the width of the rows in the profile relative to the profile range.
Profile Horizontal Offset: Adjusts the horizontal offset of the profile when it is selected to be displayed on the right side of the chart.
Value Area Background: Toggles the visibility of the value area background and allows customization of the fill color.
Profile Background: Toggles the visibility of the profile background and allows customization of the fill color.
🔶 RELATED SCRIPTS
Supply-Demand-Profiles
Liquidity-Sentiment-Profile
Thanks to our community for recommending this script. For more conceptual scripts and related content, we welcome you to explore by visiting >>> LuxAlgo-Scripts .
High Volume AlertThe High Volume Alert Script is developed for all traders focusing on volume analysis in their trading strategies, providing alerts for unusually high trading volumes during specified trading sessions.
Functionality:
Volume Moving Average Calculation:
Average Volume = Moving Average(Volume) = Sum of last the x last candles Volume
Where n is the user-defined period for the moving average calculation (denoted as movingaverageinput in the script. This moving average serves as the baseline to compare current volume levels against historical averages.
High Volume Detection:
HighVolume = CurrentVolume >= (MA(Volume) x HighVolumeRatio)
Here, HighVolumeRatio is a user-defined multiplier that sets the threshold for what is considered high volume. If the current volume exceeds this threshold (the product of the moving average of volume and the HighVolumeRatio ), the script identifies this as a high-volume event.
Session Filtering:
The script further refines these alerts by ensuring they only trigger during the specified trading session, enhancing relevance for traders interested in specific market hours. This session is defined by the sess and timezone parameters.
Visualisation and Alerts:
If high volume is detected (HighVolume = True), the script colors the volume bar with the highVolumeColor . If the option is selected, it also changes the color of the candlestick to either highVolumeCandleColorUp (for bullish candles) or highVolumeCandleColorDown (for bearish candles), depending on the price movement within the high-volume period. An alert is generated through the alertcondition function when high volume is detected during the specified session, notifying the trader of potentially significant market activity.
Application in Trading:
This indicator serves traders who prioritize volume as a leading indicator of potential price movement. High trading volumes may indicate the presence of significant market activity, often associated with events like news releases, market openings, or large trades, which can precede price movements.
Originality and Practicality:
This script is self-developed, aiming to fill the gap in automatic ratio adjusted volume alerts within the TradingView environment.
Conclusion:
The High Volume Alert Script is an essential tool for traders who integrate volume analysis into their strategy, offering tailored alerts and visual cues for high volume periods.
Compliance and Limitations:
The script complies with TradingView scripting standards, ensuring no lookahead bias and maintaining real-time data integrity. However, its utility depends on the availability on volume data, and please be aware that forex pairs never offer real volume data, this tool is best used with a exchange traded symbol.
Bond Yield SpreadThe Bond Yield Spread Script is developed for forex traders, offering an automated tool to calculate the bond yield spread between two countries associated with the forex pair displayed on the chart.
Functionality:
The script starts by identifying the base and quote currencies of the current forex pair and aligns them with their corresponding national bond symbols based on user-selected maturity, with options ranging from 01Y to 30Y. It calculates the yield spread by subtracting the bond yield associated with the quote country from that of the base country, following the formula:
Yield Spread = Yield(Base Country) − Yield(Quote Country)
which is then displayed as a plot line on the chart.
This script relies solely on TradingView's internal yield symbols, with the following calculation:
"currency" => "first two letters" + maturity
And maturity, in this case, is the value that is configured in the indicator settings, for example:
"EUR" => "EU" + "02Y" will result in EU02Y -> which will be used in the formula, depending on the quote or base currency.
Application in Trading:
This indicator is invaluable for traders employing carry trading strategies or assessing currency strength based on traded interest rates as an indicator. A higher yield spread typically indicates a stronger currency, because the return obtained for holding the currency is higher.
Originality and Practicality:
This script is self-developed, aiming to fill the gap in automatic bond yield comparisons within the TradingView environment. It is particularly beneficial for traders focusing on macroeconomic factors affecting forex markets. Unlike other scripts, it integrates various bond maturities into one tool, enhancing its utility and application range.
Conclusion:
Designed for traders incorporating macroeconomics in their strategy, this script will be useful to calculate the bond yield differences automatically without having to enter a new formula for every new currency pair.
Compliance and Limitations:
The script complies with TradingView scripting standards, ensuring no lookahead bias and maintaining real-time data integrity. However, its utility depends on the comprehensive availability of bond yield data within TradingView. As not all countries issue bonds for each listed maturity, this may limit the script’s application for certain currency pairs or specific maturities.
RAINBOW AVERAGES - INDICATOR - (AS) - 1/3
-INTRODUCTION:
This is the first of three scripts I intend to publish using rainbow indicators. This script serves as a groundwork for the other two. It is a RAINBOW MOVING AVERAGES indicator primarily designed for trend detection. The upcoming script will also be an indicator but with overlay=false (below the chart, not on it) and will utilize RAINBOW BANDS and RAINBOW OSCILLATOR. The third script will be a strategy combining all of them.
RAINBOW moving averages can be used in various ways, but this script is mainly intended for trend analysis. It is meant to be used with overlay=true, but if the user wishes, it can be viewed below the chart. To achieve this, you need to change the code from overlay=true to false and turn off the first switch that plots the rainbow on the chart (or simply move the indicator to a new pane below). By doing this, you will be able to see how all four conditions used to detect trends work on the chart. But let's not get ahead of ourselves.
-WHAT IS IT:
In its simplest form, this indicator uses 10 moving averages colored like a rainbow. The calculation is as follows:
MA0: This is the main moving average and can be defined with the type (SMA, EMA, RMA, WMA, SINE), length, and price source. However, the second moving average (MA1) is calculated using MA0 as its source, MA2 uses MA1 as the data source, and so on, until the last one, MA9. Hence, there are 10 moving averages. The first moving average is special as all the others derive from it. This indicator has many potential uses, such as entry/exit signals, volatility indication, and stop-loss placement, but for now, we will focus on trend detection.
-TREND DETECTION:
The indicator offers four different background color options based on the user's preference:
0-NONE: No background color is applied as no trend detection tools is being used (boring)
1-CHANGE: The background color is determined by summing the changes of all 10 moving averages (from two bars). If the sum is positive and not falling, the background color is GREEN. If the sum is negative and not rising, the background color is RED. From early testing, it works well for the beginning of a movement but not so much for a lasting trend.
2-RAINBW: The background color is green when all the moving averages are in ascending order, indicating a bullish trend. It is red when all the moving averages are in descending order, indicating a bearish trend. For example, if MA1>MA2>MA3>MA4..., the background color is green. If MA1 threshold, and red indicates width < -threshold.
4-DIRECT: The background color is determined by counting the number of moving averages that are either above or below the input source. If the specified number of moving averages is above the source, the background color is green. If the specified number of moving averages is below the source, the background color is red. If all ten MAs are below the price source, the indicator will show 10, and if all ten MAs are above, it will show -10. The specific value will be set later in the settings (same for 3-TSHOLD variant). This method works well for lasting trends.
Note: If the indicator is turned into a below-chart version, all four color options can be seen as separate indicators.
-PARAMETERS - SETTINGS:
The first line is an on/off switch to plot the skittles indicator (and some info in the tooltip). The second line has already been discussed, which is the background color and the selection of the source (only used for MA0!).
The line "MA1: TYP/LEN" is where we define the parameters of MA0 (important). We choose from the types of moving averages (SMA, EMA, RMA, WMA, SINE) and set the length.
Important Note: It says MA1, but it should be MA0!.
The next line defines whether we want to smooth MA1 (which is actually MA0) and the period for smoothing. When smoothing is turned on, MA0 will be smoothed using a 3-pole super smoother. It's worth noting that although this only applies to MA0, as the other MAs are derived from it, they will also be smoothed.
In the line below, we define the type and length of MAs for MA2 (and other MAs except MA0). The same type and length are used for MA1 to MA9. It's important to remember that these values should be smaller. For example, if we set 55, it means that MA1 is the average of 55 periods of MA0, MA2 will be 55 periods of MA1, and so on. I encourage trying different combinations of MA types as it can be easily adjusted for ur type of trading. RMA looks quirky.
Moving on to the last line, we define some inputs for the background color:
TSH: The threshold value when using 3-TSHOLD-BGC. It's a good idea to change the chart to a pane below for easier adjustment. The default values are based on EURUSD-5M.
BG_DIR: The value that must be crossed or equal to the MA score if using 4-DIRECT-BGC. There are 10 MAs, so the maximum value is also 10. For example, if you set it to 9, it means that at least 9 MAs must be below/above the price for the script to detect a trend. Higher values are recommended as most of the time, this indicator oscillates either around the maximum or minimum value.
-SUMMARY OF SETTINGS:
L1 - PLOT MAs and general info tooltip
L2 - Select the source for MA0 and type of trend detection.
L3 - Set the type and length of MA0 (important).
L4 - Turn smoothing on/off for MA0 and set the period for super smoothing.
L5 - Set the type and length for the rest of the MAs.
L6 - Set values if using 4-DIRECT or 3-TSHOLD for the trend detection.
-OTHERS:
To see trend indicators, you need to turn off the plotting of MAs (first line), and then choose the variant you want for the background color. This will plot it on the chart below.
Keep in mind that M1 int settings stands for MA0 and MA2 for all of the 9 MAs left.
Yes, it may seem more complicated than it actually is. In a nutshell, these are 10 MAs, and each one after MA0 uses the previous one as its source. Plus few conditions for range detection. rest is mainly plots and colors.
There are tooltips to help you with the parameters.
I hope this will be useful to someone. If you have any ideas, feedback, or spot errors in the code, LET ME KNOW.
Stay tuned for the remaining two scripts using skittles indicators and check out my other scripts.
-ALSO:
I'm always looking for ideas for interesting indicators and strategies that I could code, so if you don't know Pinescript, just message me, and I would be glad to write your own indicator/strategy for free, obviously.
-----May the force of the market be with you, and until we meet again,
Quickfingers Luc base scanner - version 2This is my second implementation of a Pine Script Quickfingers Luc (QFL) base scanner that I have published on Trading View. QFL base scanners seek to provide buy signals according to the QFL trading strategy. To profitably trade using this script you should be familiar with the QFL trading strategy, scaling in and out of positions, and money risk management.
Background
All the QFL base identification Pine Scripts that I have inspected to date use a simple candlestick pattern of two lower lows followed by two higher lows to identify a base. Some scripts may combine this with a volume indicator as well. In practice, I found the results of this approach to be somewhat unreliable. The candlestick pattern may identify some significant bases, may identify minor bases (that should not be traded), but at the same time miss other significant bases entirely!
My first QFL base scanner sought to use Pine Script’s built in ta.lowest and ta.highest functions to identify bases and peaks. This approach depended on the time period selected to find the lowest lows and highest highs. This approach can be problematic because significant bases may be formed outside the nominated time period, leading to the identification of minor bases within the time period. I have left the first version of my QFL base scanning script in the Trading View indicators because it uses a different approach to this script that other people may still find useful.
My second version of the QFL base scanner does not use the Pine Script ta.lowest and ta.highest functions, and therefore does not rely on nominating a time period to look back through data.
User inputs
This script steps through the price data to find the following patterns that are used to confirm bases and peaks.
Base – bounce of x% above previous base confirms that base
Peak – fall of y% below previous peak confirms that peak
Buy signal – fall of z% below the base signals a buy signal.
x%, y% and z% are user configurable through the script settings. Small percentages will provide more, but riskier, buy signals; larger percentages will provide fewer, but safer, buy signals.
The script identifies QFL bases and buy signals and marks them on the price chart. These are able to be turned on and off in the script settings. The settings also allow the user to turn on plots for peaks, lowest lows and highest highs. These are not useful for applying the QFL trading strategy, but are calculations used in finding bases and can be useful for the user to understand what the script is doing in the background.
Troubleshooting
If looking at the past script results, you may think that the script is perfectly timing entry points at the bottom of market dips. This is NOT the case. The script is actually showing buy signals when the price falls z% below the PREVIOUS base. The current base is only retrospectively marked some periods later once the reversal is confirmed – a solid line marks a confirmed base in real time; a dotted line retrospectively repaints the line to the actual base. New bases are not tradeable using this script, but a percentage fall from the previous base is – this is the QFL trading strategy.
Pine Script may flag that this script has a repainting issue. Pine Script defines repainting as, “script behavior causing historical vs realtime calculations or plots to behave differently.” In the case of this script, bases are confirmed once the price has bounced x% off the low. The script then repaints a dotted line from the base that has been identified in real time (with a solid line) back to the point in the price data where the base actually occurs. The dotted line only aids in visual identification of the base, and does not impact on the real time identification of bases. A similar repainting issue occurs for identifying peaks. I have identified the lines in the script that cause this repainting. These lines can be commented out without affecting the buy signals generated by the script, but you will also lose the visual pinpointing of historical bases and peaks.
The user may find price charts where they think that the script has not correctly identified a base or peak. Usually, careful measurement will reveal that the price chart has not confirmed a base or peak by moving x% or y% from the previous base or peak respectively.
And before you ask, yes, Trading View alerts work with this script.
Enjoy.

™TradeChartist Fib Extensions™TradeChartist Fib Extensions is a free to use script that helps traders plot Fibonacci Extensions on chart. Even though Trading View has a Fib extensions tool, some traders may prefer a plotting script like this with Fib plot lines extending across the whole of the chart to track historic prices in relation to Fib extensions drawn.
----To draw Fib extensions for uptrend ,
1. Choose a Pivot Low point (LL or a HL) as Pivot 1
2. Choose a Pivot High point (must be higher than Pivot 1) as Pivot 2
3. Choose a Pivot Low point (must be lower than Pivot 2, must be Higher than Pivot 1)
----To draw Fib extensions for downtrend,
1. Choose a Pivot High point (HH or a LH) as Pivot 1
2. Choose a Pivot Low point (must be lower than Pivot 1) as Pivot 2
3. Choose a Pivot High point (must be higher than Pivot 2 and lower than Pivot 1)
Negative extensions of -23.6% and -61.8% fib plots may be useful for some to spot reversals or to set stop losses.
Higher levels can be used if price goes beyond 161.8%
This is a free to use indicator. Give a thumbs up or leave a comment if you like the script
Check my 'Scripts' page to see other published scripts. Get in touch with me if you would like access to my invite-only scripts for a trial before deciding on a paid access for a period of your choice. Half-Yearly, Annual and Lifetime access available on invite-only scripts along with 1hr Team Viewer intro session.

Plan Limit TimerA Pine Script library that helps developers monitor script execution time against TradingView's plan-specific timeout limits. Displays a visual debug table with runtime metrics, percentage of limit consumed, and color-coded status warnings.
WHAT THIS LIBRARY DOES
TradingView enforces different script timeout limits based on subscription tier:
• Basic : 20 seconds
• Essential / Plus / Premium : 40 seconds
• Ultimate : 100 seconds
This library measures your script's total execution time and displays it relative to these limits, helping you optimize indicators for users on different plans.
THE DEBUG TABLE
When enabled, a table appears on your chart showing:
• Plan : The selected TradingView subscription tier
• Limit : Maximum allowed execution time for that plan
• Runtime : Measured script execution time
• Per Bar : Average time spent per bar
• Bars : Number of bars processed
• % Used : Percentage of timeout limit consumed (color-coded)
• Status : OK (green), WARNING (yellow), DANGER (orange), or EXCEEDED (red)
HOW IT WORKS
The library captures a timestamp at the start of your script using timenow, then calculates the elapsed time at the end. It compares this against the selected plan's timeout limit to determine percentage used and status.
Technical Note : Pine Script's timenow variable has approximately 1-second precision. Scripts that execute in under 1 second may display 0ms. This is a platform limitation, not a library issue. For detailed per-function profiling, use TradingView's built-in Pine Profiler (More → Profiler mode in the Editor).
EXPORTED FUNCTIONS
startTimer()
Call at the very beginning of your script. Returns a timestamp.
getStats(startTime, plan)
Calculates timing statistics. Returns a TimingStats object with all metrics.
showTimingTable(stats, plan, tablePosition, showOnlyOnLast)
Renders the debug table on the chart.
debugTiming(startTime, plan, tablePosition)
Convenience function combining getStats() and showTimingTable() in one call.
isApproachingLimit(stats, threshold)
Returns true if execution time has reached the specified percentage of the limit.
getRemainingMs(stats)
Returns milliseconds remaining before timeout.
formatSummary(stats)
Returns a compact single-line string for labels or tooltips.
addTimingLabel(stats, barIdx, price, labelStyle, textSize)
Creates a color-coded chart label displaying timing statistics. Useful for visual debugging without the full table. Returns the label object for further customization.
EXPORTED CONSTANTS
• LIMIT_BASIC = 20
• LIMIT_ESSENTIAL = 40
• LIMIT_PLUS = 40
• LIMIT_PREMIUM = 40
• LIMIT_ULTIMATE = 100
EXPORTED TYPE: TimingStats
Object containing:
• totalTimeMs (float): Total execution time in milliseconds
• timePerBarMs (float): Average time per bar
• barsTimed (int): Number of bars measured
• barsSkipped (int): Bars excluded from measurement
• planLimitMs (int): Plan timeout in milliseconds
• percentUsed (float): Percentage of limit consumed
• status (string): "OK", "WARNING", "DANGER", or "EXCEEDED"
HOW TO USE IN YOUR INDICATOR
//@version=6
indicator("My Indicator", overlay = true)
import YourUsername/PlanLimitTimer/1 as timer
// User selects their TradingView plan
planInput = input.string("basic", "Your Plan", options = )
// START TIMING - must be first
startTime = timer.startTimer()
// Your indicator calculations here
sma20 = ta.sma(close, 20)
rsi14 = ta.rsi(close, 14)
plot(sma20)
// END TIMING - must be last
timer.debugTiming(startTime, planInput)
ADVANCED USAGE EXAMPLE
//@version=6
indicator("Advanced Example", overlay = true)
import YourUsername/PlanLimitTimer/1 as timer
planInput = input.string("basic", "Plan", options = )
startTime = timer.startTimer()
// Your calculations...
sma = ta.sma(close, 200)
plot(sma)
// Get stats for programmatic use
stats = timer.getStats(startTime, planInput)
// Option 1: Use addTimingLabel for a quick visual indicator
if barstate.islast
timer.addTimingLabel(stats, bar_index, high)
// Option 2: Show custom warning label if approaching limit
if timer.isApproachingLimit(stats, 70.0) and barstate.islast
label.new(bar_index, low, "Warning: " + timer.formatSummary(stats),
color = color.orange, textcolor = color.white, style = label.style_label_up)
// Display the debug table
timer.showTimingTable(stats, planInput, position.bottom_right)
IMPORTANT LIMITATIONS
1. Precision : Timing precision is approximately 1 second due to timenow behavior. Fast scripts show 0ms.
2. Variability : Results vary based on TradingView server load. The same script may show different times across runs.
3. Total Time Only : This library measures total script execution time, not individual function timing. For per-function analysis, use the Pine Profiler in the Editor.
4. Historical Bars : On historical bars, timenow reflects when the script loaded, not individual bar processing times.
USE CASES
• Optimization Debugging : See how close your script is to timeout limits
• Multi-Plan Support : Help users select appropriate settings for their subscription tier
• Performance Regression : Detect when changes increase execution time
• Documentation : Show users the performance characteristics of your indicator

Volume essential parameters overlayVolume EPO – Essential Volume Parameters Overlay
1. Motivation and design philosophy
Volume EPO is designed as a conceptual overlay rather than a self contained trading system. The main idea behind this script is to take complex, foundational market concepts out of heavy, menu driven strategies and express them as lightweight, independent layers that sit on top of any chart or indicator.
In many TradingView scripts, a single strategy tries to handle everything at once: signal logic, risk settings, visual cues, multi timeframe controls, and conceptual explanations. This usually leads to long input menus, performance issues, and difficult maintenance. The architectural approach behind Volume EPO is the opposite: keep the core strategy lean, and move the explanation and measurement of key concepts into dedicated overlays.
In this framework, Volume EPO is the base layer for the concept of volume. It does not decide anything about entries or exits. Instead, it exposes and clarifies how different definitions of volume behave candle by candle. Other layers or strategies can then build on top of this understanding.
2. What Volume EPO does
Volume EPO focuses on four essential volume parameters for each bar:
- Buy volume - Sell volume - Total volume - Delta volume (the difference between buy and sell volume)
The script presents these parameters in a compact heads up display (HUD) table that can be positioned anywhere on the chart. It is designed to be visually minimal, language aware, and usable on top of any other indicator or price action without cluttering the view.
The indicator does not output signals, alerts, arrows, or strategy entries. It is a descriptive and educational tool that shows how volume is distributed, not a prescriptive tool that tells the trader what to do.
3. Two definitions of volume
A central theme of this script is that there is more than one way to define and interpret “volume” inside a single candle. Volume EPO implements and clearly separates two different approaches:
- A geometric, candle based approximation that uses only OHLC and volume of the current bar. - An intrabar, data driven definition that uses lower timeframe up and down volume when it is available.
The user can switch between these modes via the calculation method input. The mode is prominently shown inside the on chart table so that the context is always explicit.
3.1 Geometry mode (Source File, approximate)
In Geometry mode, Volume EPO works only with the current bar’s OHLC values and total volume. No lower timeframe data is required.
The candle’s range is defined as high minus low. If the range is positive, the position of the close inside that range is used as a simple model for how volume might have been distributed between buyers and sellers:
- The closer the close is to the high, the more of the total volume is attributed to the buying side. - The closer the close is to the low, the more of the total volume is attributed to the selling side. - In a rare case where the bar has no price range (for example a flat or doji bar), total volume is split evenly between buy and sell volume.
From this model, the script derives:
- Buy volume (approximated) - Sell volume (approximated) - Total volume (as reported by the bar) - Delta volume as the difference between buy and sell volume
This approach is intentionally labeled as “Geometry (Approx)” in the HUD. It is a theoretical reconstruction based solely on the candle’s geometry and total volume, and it is always available on any market or timeframe that provides OHLCV data.
3.2 Intrabar mode (Precise)
In Intrabar mode, Volume EPO uses the TradingView built in library for up and down volume on a user selected lower timeframe. Instead of inferring volume from the shape of the candle, it reads the underlying lower timeframe data when that data is accessible.
The script requests up and down volume from a lower timeframe such as 15 seconds, using the official TA library functions. The results are then interpreted as follows:
- Buy volume is taken as the absolute value of the up volume. - Sell volume is taken as the absolute value of the down volume. - Total volume is the sum of buy and sell volume. - Delta volume is provided directly by the library as the difference between up and down volume.
If valid lower timeframe data exists for a bar, the bar is counted as covered by Intrabar data. If not, that bar is marked as invalid for this precise calculation and is excluded from the covered count.
This mode is labeled “Precise” in the HUD, together with the selected lower timeframe, because it is anchored in actual intrabar data rather than in a geometric model. It provides a closer view of how buying and selling pressure unfolded inside the bar, at the cost of requiring more data and being dependent on the availability of that data.
4. Coverage, lookback, and what the numbers mean
The top part of the HUD reports not only which volume definition is active, but also an additional line that describes the effective coverage of the data.
In Intrabar (Precise) mode, the script displays:
- “Scanned: N Bars”
Here, N counts how many bars since the indicator was loaded have successfully received valid lower timeframe delta data. It is a measure of how much of the visible history has been truly covered by intrabar information, not a lookback window in the sense of a rolling calculation.
In Geometry mode, the script displays:
- “Lookback: L Bars”
In this extracted layer, the lookback value L is purely descriptive. It does not change how the current bar’s volume is computed, and it is not used in any iterative or statistical calculation inside this script. It is meant as a conceptual label, for example to keep the volume layer consistent with a broader framework where lookback length is a structural parameter.
Summarizing these two fields:
- Scanned tells you how many bars have been processed using real intrabar data. - Lookback is a descriptive parameter in Geometry mode in this specific overlay, not a direct driver of the computations.
5. The HUD layout on the chart
The on chart table is intentionally compact and structured to be read quickly:
- Header: a title identifying the overlay as Volume EPO. - Mode line: explicitly states whether the script is in Precise or Geometry mode, and for Precise mode also shows the lower timeframe used. - Coverage line: - In Precise mode, it shows “Scanned: N Bars”. - In Geometry mode, it shows “Lookback: L Bars”. - Volume block: - A line for buy and sell volume, marked with clear directional symbols. - A line for total volume and the absolute delta, accompanied by the sign of the delta. - Numeric formatting uses human friendly suffixes (for example K, M, B) to keep the display readable. - Footer: the current symbol and a time stamp, adjusted by a user selectable timezone offset so that the HUD can be aligned with the trader’s local time reference.
The table can be positioned anywhere on the chart and resized via inputs, and it supports multiple color themes and languages in order to integrate cleanly into different chart layouts.
6. How to use Volume EPO in practice
Volume EPO is meant to be read together with price action and other tools, not in isolation. Typical uses include:
- Studying how often a strong directional candle is actually supported by dominant buy or sell volume. - Comparing the behavior of delta volume between Geometry and Intrabar definitions. - Building a personal intuition for how intrabar data refines or contradicts the simple candle based approximation. - Feeding these insights into separate, lean strategy scripts that do not need to carry the full explanatory logic of volume inside them.
Because it is an overlay layer, Volume EPO can be stacked with other custom indicators without adding new signals or complexity to their logic. It simply adds a clear and consistent view of volume behavior on top of whatever the trader is already watching.
7. Educational and non signalling nature
Finally, it is important to stress that Volume EPO is not a trading system, not a signal generator, and not financial advice. The script does not tell the user when to enter or exit. It only reports how different definitions of volume describe the current bar.
Deciding whether to trade, how to trade, and which risk parameters to use remains entirely with the user and with their own strategy. Volume EPO provides context and clarity around the concept of volume so that those decisions can be informed by a better understanding of how buying and selling pressure is structured inside each candle.
Note: Even on lower timeframes, every reconstruction of volume remains an approximation, except at the true single tick level. However, the closer the chosen lower timeframe is to a one tick stream, the more accurately it can reflect the underlying order flow and balance between buying and selling pressure.

able MACD Overview
Purpose: The indicator combines the traditional MACD (Moving Average Convergence Divergence) with a short-term “forecast” (projection) of MACD/histogram values to give early warning of momentum changes.
Typical outputs:
MACD line (fastEMA − slowEMA)
Signal line (EMA of MACD)
Histogram (MACD − signal)
Forecasted MACD or histogram projected N bars ahead
Optional buy/sell markers and alert conditions
Add the indicator to TradingView (Installation)
Open TradingView and the chart you want to apply the indicator to.
Click “Pine Editor” at the bottom of the chart.
Copy the contents of able_macd_forecast.pine into the Pine Editor window.
Click “Add to chart” (or Save then Add to chart). If it’s a study, it will appear on the chart below price.
If you plan to re-use the script, click Save and give it a meaningful name.
Inputs / Parameters (typical) Note: exact input names may differ in your script. Replace the names below with the script’s input labels when you inspect it.
Source: price source for calculations (close, hl2, etc.).
Fast Length: length for the fast EMA (commonly 12).
Slow Length: length for the slow EMA (commonly 26).
Signal Length: length for the MACD signal EMA (commonly 9).
Forecast Length / Horizon: how many bars ahead the script projects the MACD/histogram (e.g., 1–5).
Forecast Method / Smoothing: choice of projection method (linear regression, EMA extrapolation, simple slope * N, etc.) if available.
Histogram Thresholds: numeric thresholds to emphasize significant momentum (optional).
Show Forecast: toggle on/off the forecast plot.
Alerts On/Off toggles: enable or disable alert conditions baked into the indicator.
Visual / Style settings: colors, plot thickness, histogram style (columns/areas), show labels, show buy/sell arrows.
How the indicator is typically calculated (summary)
MACD line = EMA(source, fast) − EMA(source, slow)
Signal line = EMA(MACD line, signal length)
Histogram = MACD − Signal
Forecast = method-specific short-term projection of MACD or histogram (for example: extend the last slope forward, apply linear regression to MACD values and extrapolate N bars, or apply an additional smoothing and extend that value) Note: For exact math, I need to inspect the script; this is the typical approach.
How to read the indicator (signals & interpretation)
Bullish signal:
MACD line crossing above the signal line (MACD cross up).
Histogram turns positive (cross above zero).
Forecast shows MACD/histogram moving higher in the next N bars (if forecast is positive or trending up).
Bearish signal:
MACD line crossing below the signal line (MACD cross down).
Histogram turns negative (cross below zero).
Forecast shows MACD/histogram moving lower ahead.
Confirmations:
Use price action (higher highs/lows for bullish, lower highs/lows for bearish).
Volume or other momentum/confluence indicators (RSI, ADX).
Divergences:
Bullish divergence: price makes lower low while MACD histogram makes higher low.
Bearish divergence: price makes higher high while MACD histogram makes lower high.
Forecast behavior:
If the forecast leads the MACD cross (forecast crosses before the current MACD does), it’s an early warning.
Use caution: forecasts are prone to false signals; always confirm.
Common trading setups using this indicator
Conservative:
Wait for MACD to cross signal + histogram above zero + forecast already trending same direction.
Use stop below recent swing low (for long) or above recent swing high (for short).
Aggressive (early entry):
Enter when forecast turns positive while MACD still below signal (anticipating cross).
Use tighter stops and smaller position sizes.
Exit rules:
Opposite MACD cross, histogram flipping sign, or a target based on risk-reward.
Use trailing stop based on ATR or structure.
Example settings for different timeframes (starting points)
Scalping / 5–15 min:
Fast 8, Slow 21, Signal 5, Forecast 1–2
Intraday / 1H:
Fast 12, Slow 26, Signal 9, Forecast 2–3
Swing / 4H–Daily:
Fast 12, Slow 26, Signal 9, Forecast 3–5 Adjust based on the asset volatility and backtests.
Adding alerts (TradingView)
Click the “Alerts” button (clock icon) or press Alt + A.
In the Condition dropdown, select the indicator name (able_macd_forecast) and choose a plotted series or built-in alert condition (if the script uses alertcondition).
Common alert types:
MACD crosses Signal (Crossing)
Histogram crosses 0 (Crossing)
Forecast crosses 0 or Forecast trend change (if provided)
Message templates:
“{{ticker}}: MACD crossed above signal on {{interval}}”
“{{ticker}} Forecast positive: MACD forecast shows upward momentum”
Customize the message for your trade automation or notifications.
Configure frequency (Only once, Once per bar, or Once per bar close) — for signals like crossovers, “Once per bar close” is usually safer to avoid repainting issues. Note: If the script includes alertcondition() calls with explicit IDs/messages, use those directly — they are the most reliable for automation.
Backtesting / Strategy conversion
If this script is a study (indicator), you can:
Convert it to a strategy by adding strategy.* order calls (strategy.entry, strategy.close) using the entry/exit logic you prefer, or
Use TradingView’s “Bar Replay” to manually test signals across different markets/timeframes.
If you want, I can help convert or write a strategy wrapper that uses the indicator’s signals to place backtest trades (I’ll need the code).
Practical tips & best practices
Use higher timeframe confirmation for lower-timeframe entries (e.g., check daily MACD momentum before trading 15m signals).
Beware of choppy markets; MACD / forecast may produce whipsaws. Combine with trend filters (moving average direction, ADX).
If you rely on forecasted values, prefer alerts “on bar close” when possible to reduce false alerts from intra-bar noise.
Tune parameters for the specific asset (FX, crypto, stocks have different behavior).
Record each signal and outcome for a sample period (20–100 trades) to evaluate performance.
Troubleshooting
Indicator won’t add: verify Pine version in script header (//@version=4 or //@version=5). TradingView may reject scripts with unsupported version syntax.
Plots missing: check script inputs (Some scripts hide plots if toggles are off).
Alerts firing too often: change alert frequency to “Once per bar close” or adjust threshold values.
Forecast seems to repaint: some forecast methods can repaint (use “bar_index” or store values only on closed bars, or use non-repainting forecast methods). Ask me to inspect the script for repainting logic.
What I can do next (recommended)
If you paste the content of able_macd_forecast.pine here, I will:
Produce a precise, line-by-line usage guide mapping to the exact input names and default values.
Show the exact plotted series names and how to reference them for alerts.
Point out any repainting risks and suggest fixes.
Provide example alert messages that match the script’s alertcondition IDs (if any).
Optionally convert it into a strategy for backtesting, or add non-repainting forecast logic if needed.

Multi-Timeframe Continuity Custom Candle ConfirmationMulti-Timeframe Continuity Custom Candle Confirmation
Overview
The Timeframe Continuity Indicator is a versatile tool designed to help traders identify alignment between their current chart’s candlestick direction and higher timeframes of their choice. By coloring bars on the current chart (e.g., 1-minute) based on the directional alignment with selected higher timeframes (e.g., 10-minute, daily), this indicator provides a visual cue for confirming trends across multiple timeframes—a concept known as Timeframe Continuity. This approach is particularly useful for day traders, swing traders, and scalpers looking to ensure their trades align with broader market trends, reducing the risk of trading against the prevailing momentum.
Originality and Usefulness
This indicator is an original creation, built from scratch to address a common challenge in trading: ensuring that price action on a lower timeframe aligns with the trend on higher timeframes. Unlike many trend-following indicators that rely on moving averages, oscillators, or other lagging metrics, this script directly compares the bullish or bearish direction of candlesticks across timeframes. It introduces the following unique features:
Customizable Timeframes: Users can select from a range of higher timeframes (5m, 10m, 15m, 30m, 1h, 2h, 4h, 1d, 1w, 1M) to check for alignment, making it adaptable to various trading styles.
Neutral Candle Handling: The script accounts for neutral candles (where close == open) on the current timeframe by allowing them to inherit the direction of the higher timeframe, ensuring continuity in trend visualization.
Table: A table displays the direction of each selected timeframe and the current timeframe, helping identify direction in the event you don't want to color bars.
Toggles for Flexibility: Options to disable bar coloring and the debug table allow users to customize the indicator’s visual output for cleaner charts or focused analysis.
This indicator is not a mashup of existing scripts but a purpose-built tool to visualize timeframe alignment directly through candlestick direction, offering traders a straightforward way to confirm trend consistency.
What It Does
The Timeframe Continuity Indicator colors bars on your chart when the direction of the current timeframe’s candlestick (bullish, bearish, or neutral) aligns with the direction of the selected higher timeframes:
Lime: The current bar (e.g., 1m) is bullish or neutral, and all selected higher timeframes (e.g., 10m) are bullish.
Pink: The current bar is bearish or neutral, and all selected higher timeframes are bearish.
Default Color: If the directions don’t align (e.g., 1m bar is bearish but 10m is bullish), the bar remains the default chart color.
The indicator also includes a debug table (toggleable) that shows the direction of each selected timeframe and the current timeframe, helping traders diagnose alignment issues.
How It Works
The script uses the following methodology:
1. Direction Calculation: For each timeframe (current and selected higher timeframes), the script determines the candlestick’s direction:
Bullish (1): close > open / Bearish (-1): close < open / Neutral (0): close == open
Higher timeframe directions are fetched using Pine Script’s request.security function, ensuring accurate data retrieval.
2. Alignment Check: The script checks if all selected higher timeframes are uniformly bullish (full_bullish) or bearish (full_bearish).
o A higher timeframe must have a clear direction (bullish or bearish) to trigger coloring. If any selected timeframe is neutral, alignment fails, and no coloring occurs.
3. Coloring Logic: The current bar is colored only if its direction aligns with the higher timeframes:
Lime if the higher timeframes are bullish and the current bar is bullish or neutral.
Maroon if the higher timeframes are bearish and the current bar is bearish or neutral.
If the current bar’s direction opposes the higher timeframe (e.g., 1m bearish, 10m bullish), the bar remains uncolored.
Users can disable bar coloring entirely via the settings, leaving bars in their default chart color.
4. Direction Table:
A table in the top-right corner (toggleable) displays the direction of each selected timeframe and the current timeframe, using color-coded labels (green for bullish, red for bearish, gray for neutral).
This feature helps traders understand why a bar is or isn’t colored, making the indicator accessible to users unfamiliar with Pine Script.
How to Use
1. Add the Indicator: Add the "Timeframe Continuity Indicator" to your chart in TradingView (e.g., a 1m chart of SPY).
2. Configure Settings:
Timeframe Selection: Check the boxes for the higher timeframes you want to compare against (default: 10m). Options include 5m, 10m, 15m, 30m, 1h, 2h, 4h, 1D, 1W, and 1M. Select multiple timeframes if you want to ensure alignment across all of them (e.g., 10m and 1d).
Enable Bar Coloring: Default: true (bars are colored lime or maroon when aligned). Set to false to disable coloring and keep the default chart colors.
Show Table: Default: true (table is displayed in the top-right corner). Set to false to hide the table for a cleaner chart.
3. Interpret the Output:
Colored Bars: Lime bars indicate the current bar (e.g., 1m) is bullish or neutral, and all selected higher timeframes are bullish. Maroon bars indicate the current bar is bearish or neutral, and all selected higher timeframes are bearish. Uncolored bars (default chart color) indicate a mismatch (e.g., 1m bar is bearish while 10m is bullish) or no coloring if disabled.
Direction Table: Check the table to see the direction of each selected timeframe and the current timeframe.
4. Example Use Case:
On a 1m chart of SPY, select the 10m timeframe.
If the 10m timeframe is bearish, 1m bars that are bearish or neutral will color maroon, confirming you’re trading with the higher timeframe’s trend.
If a 1m bar is bullish while the 10m is bearish, it remains uncolored, signaling a potential misalignment to avoid trading.
Underlying Concepts
The indicator is based on the concept of Timeframe Continuity, a strategy used by traders to ensure that price action on a lower timeframe aligns with the trend on higher timeframes. This reduces the risk of entering trades against the broader market direction. The script directly compares candlestick directions (bullish, bearish, or neutral) rather than relying on lagging indicators like moving averages or RSI, providing a real-time, price-action-based confirmation of trend alignment. The handling of neutral candles ensures that minor indecision on the lower timeframe doesn’t interrupt the visualization of the higher timeframe’s trend.
Why This Indicator?
Simplicity: Directly compares candlestick directions, avoiding complex calculations or lagging indicators.
Flexibility: Customizable timeframes and toggles cater to various trading strategies.
Transparency: The debug table makes the indicator’s logic accessible to all users, not just those who can read Pine Script.
Practicality: Helps traders confirm trend alignment, a key factor in successful trading across timeframes.
Watermark with dynamic variables [BM]█ OVERVIEW
This indicator allows users to add highly customizable watermark messages to their charts. Perfect for branding, annotation, or displaying dynamic chart information, this script offers advanced customization options including dynamic variables, text formatting, and flexible positioning.
█ CONCEPTS
Watermarks are overlay messages on charts. This script introduces placeholders — special keywords wrapped in % signs — that dynamically replace themselves with chart-related data. These watermarks can enhance charts with context, timestamps, or branding.
█ FEATURES
Dynamic Variables : Replace placeholders with real-time data such as bar index, timestamps, and more.
Advanced Customization : Modify text size, color, background, and alignment.
Multiple Messages : Add up to four independent messages per group, with two groups supported (A and B).
Positioning Options : Place watermarks anywhere on the chart using predefined locations.
Timezone Support : Display timestamps in a preferred timezone with customizable formats.
█ INPUTS
The script offers comprehensive input options for customization. Each Watermark (A and B) contains identical inputs for configuration.
Watermark settings are divided into two levels:
Watermark-Level Settings
These settings apply to the entire watermark group (A/B):
Show Watermark: Toggle the visibility of the watermark group on the chart.
Position: Choose where the watermark group is displayed on the chart.
Reverse Line Order: Enable to reverse the order of the lines displayed in Watermark A.
Message-Level Settings
Each watermark contains up to four configurable messages. These messages can be independently customized with the following options:
Message Content: Enter the custom text to be displayed. You can include placeholders for dynamic data.
Text Size: Select from predefined sizes (Tiny, Small, Normal, Large, Huge) or specify a custom size.
Text Alignment and Colors:
- Adjust the alignment of the text (Left, Center, Right).
- Set text and background colors for better visibility.
Format Time: Enable time formatting for this watermark message and configure the format and timezone. The settings for each message include message content, text size, alignment, and more. Please refer to Formatting dates and times for more details on valid formatting tokens.
█ PLACEHOLDERS
Placeholders are special keywords surrounded by % signs, which the script dynamically replaces with specific chart-related data. These placeholders allow users to insert dynamic content, such as bar information or timestamps, into watermark messages.
Below is the complete list of currently available placeholders:
bar_index , barstate.isconfirmed , barstate.isfirst , barstate.ishistory , barstate.islast , barstate.islastconfirmedhistory , barstate.isnew , barstate.isrealtime , chart.is_heikinashi , chart.is_kagi , chart.is_linebreak , chart.is_pnf , chart.is_range , chart.is_renko , chart.is_standard , chart.left_visible_bar_time , chart.right_visible_bar_time , close , dayofmonth , dayofweek , dividends.future_amount , dividends.future_ex_date , dividends.future_pay_date , earnings.future_eps , earnings.future_period_end_time , earnings.future_revenue , earnings.future_time , high , hl2 , hlc3 , hlcc4 , hour , last_bar_index , last_bar_time , low , minute , month , ohlc4 , open , second , session.isfirstbar , session.isfirstbar_regular , session.islastbar , session.islastbar_regular , session.ismarket , session.ispostmarket , session.ispremarket , syminfo.basecurrency , syminfo.country , syminfo.currency , syminfo.description , syminfo.employees , syminfo.expiration_date , syminfo.industry , syminfo.main_tickerid , syminfo.mincontract , syminfo.minmove , syminfo.mintick , syminfo.pointvalue , syminfo.prefix , syminfo.pricescale , syminfo.recommendations_buy , syminfo.recommendations_buy_strong , syminfo.recommendations_date , syminfo.recommendations_hold , syminfo.recommendations_sell , syminfo.recommendations_sell_strong , syminfo.recommendations_total , syminfo.root , syminfo.sector , syminfo.session , syminfo.shareholders , syminfo.shares_outstanding_float , syminfo.shares_outstanding_total , syminfo.target_price_average , syminfo.target_price_date , syminfo.target_price_estimates , syminfo.target_price_high , syminfo.target_price_low , syminfo.target_price_median , syminfo.ticker , syminfo.tickerid , syminfo.timezone , syminfo.type , syminfo.volumetype , ta.accdist , ta.iii , ta.nvi , ta.obv , ta.pvi , ta.pvt , ta.tr , ta.vwap , ta.wad , ta.wvad , time , time_close , time_tradingday , timeframe.isdaily , timeframe.isdwm , timeframe.isintraday , timeframe.isminutes , timeframe.ismonthly , timeframe.isseconds , timeframe.isticks , timeframe.isweekly , timeframe.main_period , timeframe.multiplier , timeframe.period , timenow , volume , weekofyear , year
█ HOW TO USE
1 — Add the Script:
Apply "Watermark with dynamic variables " to your chart from the TradingView platform.
2 — Configure Inputs:
Open the script settings by clicking the gear icon next to the script's name.
Customize visibility, message content, and appearance for Watermark A and Watermark B.
3 — Utilize Placeholders:
Add placeholders like %bar_index% or %timenow% in the "Watermark - Message" fields to display dynamic data.
Empty lines in the message box are reflected on the chart, allowing you to shift text up or down.
Using \n in the message box translates to a new line on the chart.
4 — Preview Changes:
Adjust settings and view updates in real-time on your chart.
█ EXAMPLES
Branding
DodgyDD's charts
Debugging
█ LIMITATIONS
Only supports variables defined within the script.
Limited to four messages per watermark.
Visual alignment may vary across different chart resolutions or zoom levels.
Placeholder parsing relies on correct input formatting.
█ NOTES
This script is designed for users seeking enhanced chart annotation capabilities. It provides tools for dynamic, customizable watermarks but is not a replacement for chart objects like text labels or drawings. Please ensure placeholders are properly formatted for correct parsing.
Additionally, this script can be a valuable tool for Pine Script developers during debugging . By utilizing dynamic placeholders, developers can display real-time values of variables and chart data directly on their charts, enabling easier troubleshooting and code validation.